Партиции таблиц
Что такое партиции таблиц в ClickHouse?
Партиции группируют части данных таблицы в семействе MergeTree в организованные, логические единицы, что представляет собой способ организации данных, который концептуально имеет смысл и соответствует определенным критериям, таким как диапазоны времени, категории или другие ключевые атрибуты. Эти логические единицы делают данные легче управляемыми, запрашиваемыми и оптимизируемыми.
Partition By
Партиционирование может быть включено при первоначальном определении таблицы с помощью оператора PARTITION BY. Этот оператор может содержать SQL-выражение для любых колонок, результаты которого определят, к какой партиции принадлежит строка.
Чтобы проиллюстрировать это, мы улучшаем пример таблицы Что такое части таблиц, добавив оператор PARTITION BY toStartOfMonth(date), который организует части данных таблицы на основе месяцев продаж недвижимости:
Вы можете запросить эту таблицу в нашем ClickHouse SQL Playground.
Структура на диске
Каждый раз, когда набор строк вставляется в таблицу, вместо создания (по крайней мере) одной единой части данных, содержащей все вставленные строки (как описано здесь), ClickHouse создает новую часть данных для каждого уникального значения ключа партиции среди вставленных строк:
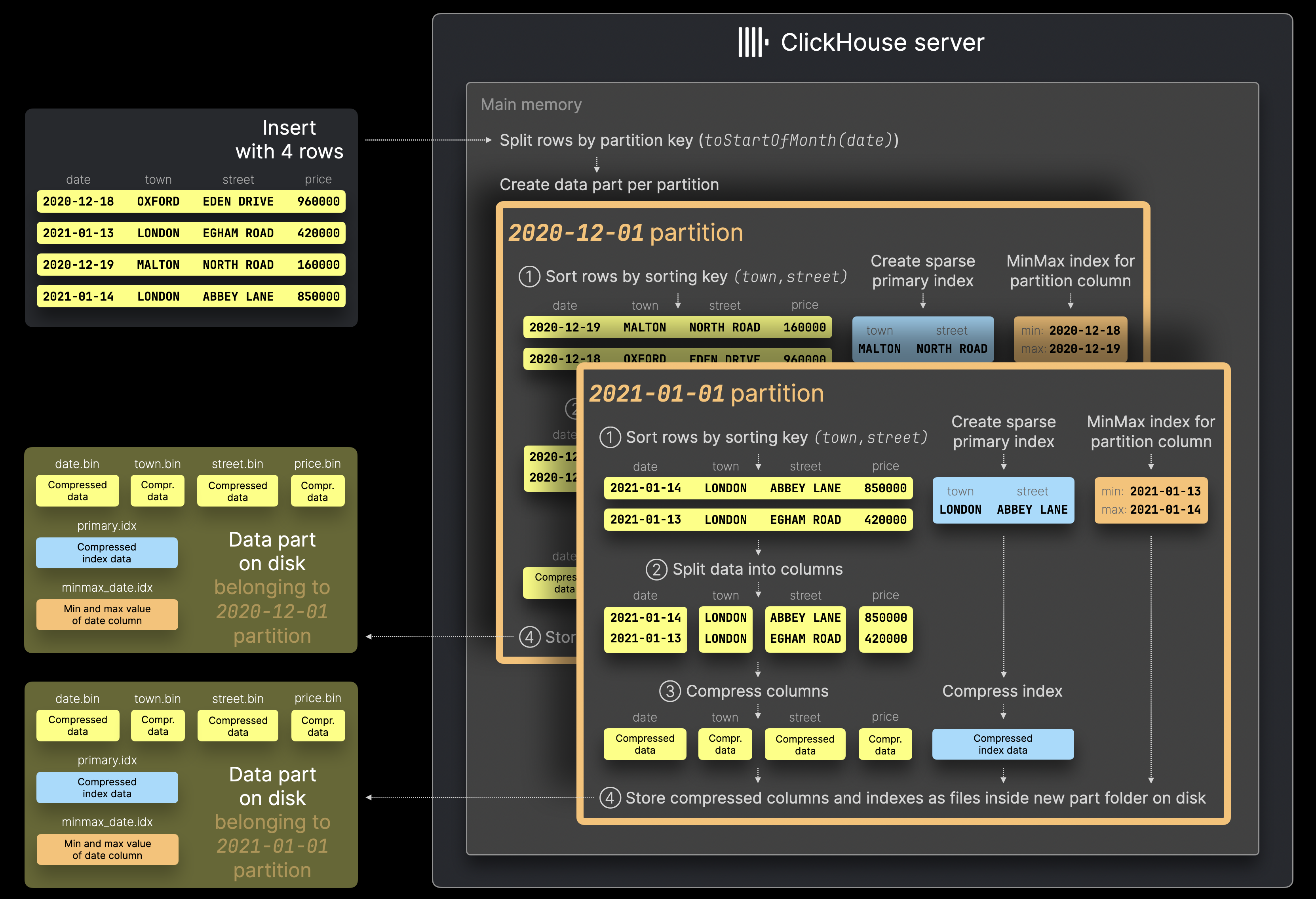
Сервер ClickHouse сначала разделяет строки из примера вставки с 4 строками, набросанными на диаграмме выше, по их значению ключа партиции toStartOfMonth(date). Затем, для каждой идентифицированной партиции строки обрабатываются как обычно с выполнением нескольких последовательных шагов (① Сортировка, ② Разделение на колонки, ③ Сжатие, ④ Запись на диск).
Обратите внимание, что при включенном партиционировании ClickHouse автоматически создает индексы MinMax для каждой части данных. Это просто файлы для каждой колонки таблицы, используемой в выражении ключа партиции, содержащие минимальные и максимальные значения этой колонки в части данных.
Слияния по партициям
С включенным партиционированием ClickHouse только сливает части данных внутри партиций, но не между партициями. Мы это иллюстрируем для нашей примерной таблицы выше:
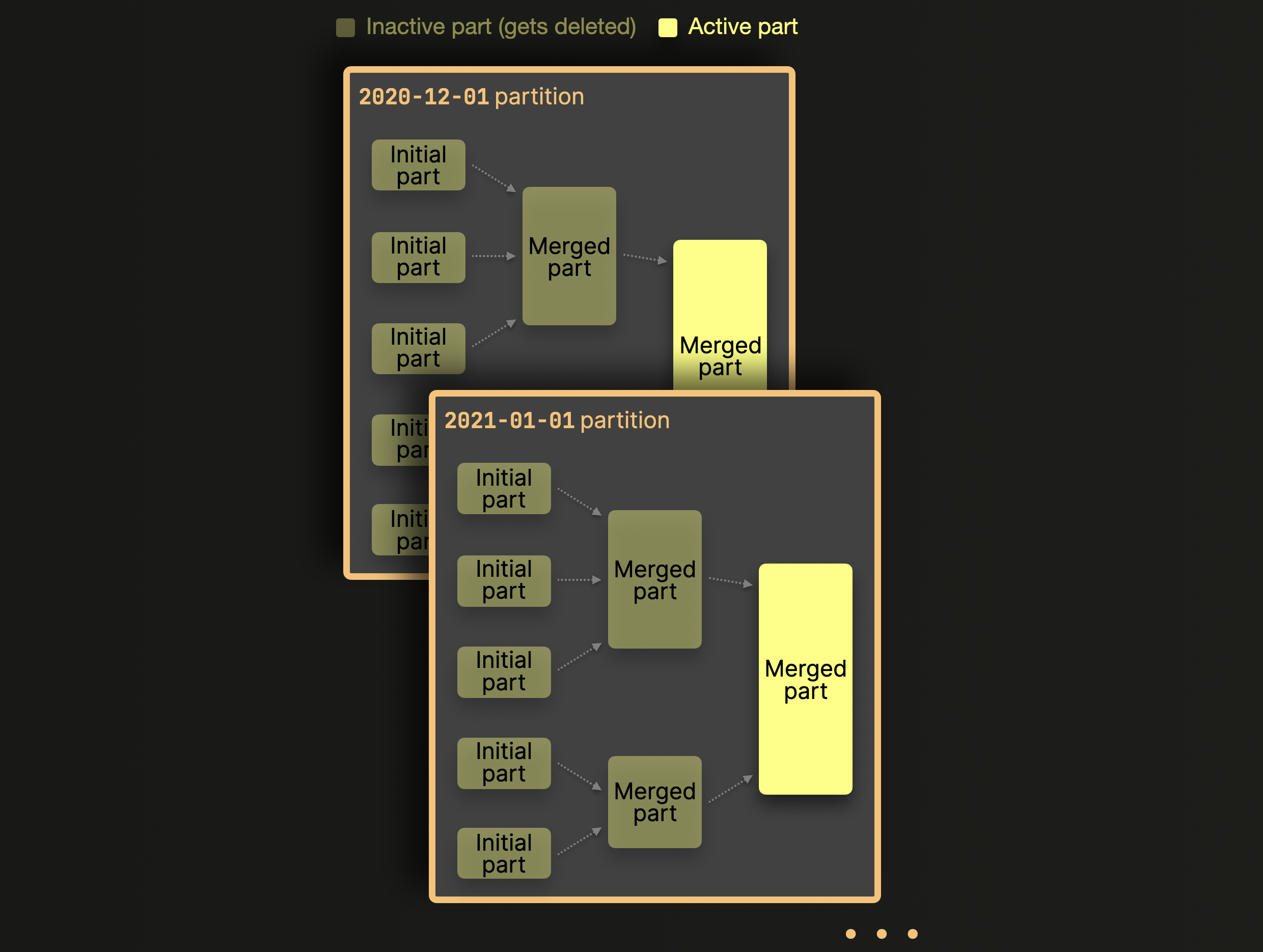
Как показано на диаграмме выше, части, принадлежащие разным партициям, никогда не сливаются. Если выбран ключ партиции с высокой кардинальностью, части, разбросанные по тысячам партиций, никогда не будут кандидатами на слияние - превышая предварительно настроенные лимиты и вызывая нежелательную ошибку Слишком много частей. Решить эту проблему просто: выберите разумный ключ партиционирования с кардинальностью менее 1000..10000.
Мониторинг партиций
Вы можете запросить список всех существующих уникальных партиций нашей примерной таблицы, используя виртуальную колонку _partition_value:
Также ClickHouse отслеживает все части и партиции всех таблиц в системной таблице system.parts, и следующий запрос возвращает для нашей примерной таблицы выше список всех партиций, а также текущее количество активных частей и сумму строк в этих частях по каждой партиции:
Для чего используются партиции таблиц?
Управление данными
В ClickHouse партиционирование является в первую очередь функцией управления данными. Организуя данные логически на основе выражения партиции, каждая партиция может управляться независимо. Например, схема партиционирования в примерной таблице выше позволяет сценариям, при которых только последние 12 месяцев данных хранятся в основной таблице, автоматически удаляя более старые данные с помощью правила TTL (см. добавленную последнюю строку команды DDL):
Поскольку таблица партиционирована по toStartOfMonth(date), целые партиции (наборы частей таблиц), которые соответствуют условию TTL, будут удалены, делая операцию очистки более эффективной, без необходимости пересоздавать части.
Аналогично, вместо удаления старых данных, их можно автоматически и эффективно перемещать на более дешевый уровень хранения:
Оптимизация запросов
Партиции могут помочь с производительностью запросов, но это сильно зависит от паттернов доступа. Если запросы нацелены только на несколько партиций (в идеале на одну), производительность может улучшиться. Это обычно полезно, если ключ партиционирования не входит в первичный ключ, и вы фильтруете по нему, как показано в примере запроса ниже.
Запрос выполняется над нашей примерной таблицей выше и вычисляет наивысшую цену всех проданных объектов недвижимости в Лондоне в декабре 2020 года, фильтруя по обоим полям (date), использованному в ключе партиционирования таблицы, и по полю (town), использованному в первичном ключе (при этом date не является частью первичного ключа).
ClickHouse обрабатывает этот запрос, применяя последовательность техник обрезки, чтобы избежать оценки нерелевантных данных:
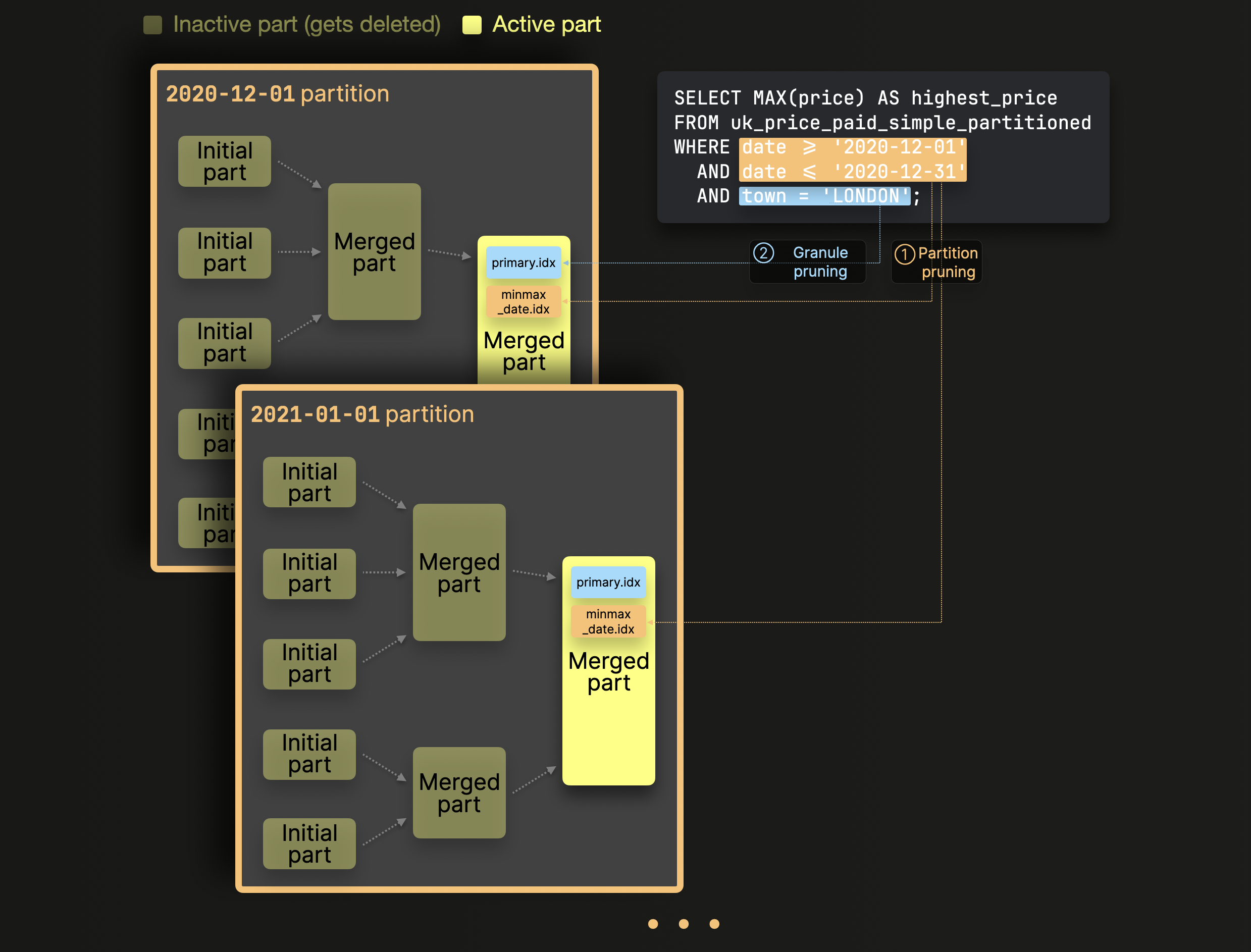
① Обрезка партиций: Индексы MinMax используются для игнорирования целых партиций (наборов частей), которые логически не могут соответствовать фильтру запроса по колонкам, используемым в ключе партиции таблицы.
② Обрезка гранул: Для оставшихся частей данных после шага ① их первичный индекс используется для игнорирования всех гранул (блоков строк), которые логически не могут соответствовать фильтру запроса по колонкам, использованным в первичном ключе таблицы.
Мы можем наблюдать эти шаги обрезки данных, исследуя план выполнения запроса для нашего примера запроса выше с использованием EXPLAIN :
Вышеуказанный вывод показывает:
① Обрезка партиций: Строки с 7 по 18 в выводе EXPLAIN показывают, что ClickHouse сначала использует индекс MinMax для поля date, чтобы определить 11 из 3257 существующих гранул (блоков строк), хранящихся в 1 из 436 существующих активных частей данных, которые содержат строки, соответствующие фильтру по date.
② Обрезка гранул: Строки с 19 по 24 в выводе EXPLAIN указывают на то, что ClickHouse затем использует первичный индекс (созданный по полю town) части данных, идентифицированной на шаге ①, чтобы еще больше сократить количество гранул (которые также могут содержать строки, соответствующие фильтру по town) с 11 до 1. Это также отражается в выводе ClickHouse-клиента, который мы распечатали выше для выполненного запроса:
Это означает, что ClickHouse просканировал и обработал 1 гранулу (блок 8192 строк) за 6 миллисекунд для вычисления результата запроса.
Партиционирование является в первую очередь функцией управления данными
Учтите, что выполнение запроса через все партиции обычно медленнее, чем выполнение того же запроса на непартиционированной таблице.
С партиционированием данные обычно распределяются по большему количеству частей данных, что часто приводит к тому, что ClickHouse сканирует и обрабатывает больший объем данных.
Мы можем продемонстрировать это, выполнив один и тот же запрос на обеих таблицах: Что такое части таблиц (без включенного партиционирования) и нашей текущей примерной таблице выше (с включенным партиционированием). Обе таблицы содержат одинаковые данные и количество строк:
Однако таблица с включенным партиционированием, имеет больше активных частей данных, потому что, как упоминалось выше, ClickHouse только сливает части данных внутри, но не между партициями:
Как показано выше, партиционированная таблица uk_price_paid_simple_partitioned имеет 306 партиций, и, следовательно, как минимум 306 активных частей данных. В то время как для нашей непартиционированной таблицы uk_price_paid_simple все начальные части данных могут быть объединены в одну активную часть посредством фоновых слияний.
Когда мы проверяем план выполнения физического запроса с использованием EXPLAIN для нашего примерного запроса выше без фильтра партиции, выполняемого на партиционированной таблице, мы можем увидеть в строках 19 и 20 ниже, что ClickHouse определил 671 из 3257 существующих гранул (блоков строк), распределённых по 431 из 436 существующих активных частей данных, которые потенциально могут содержать строки, соответствующие фильтру запроса, и, следовательно, будут просканированы и обработаны движком запросов:
План выполнения физического запроса для того же примерного запроса, выполняемого над таблицей без партиций, показывает в строках 11 и 12 ниже, что ClickHouse определил 241 из 3083 существующих блоков строк в единственной активной части данных таблицы, которые потенциально могут содержать строки, соответствующие фильтру запроса:
Для выполнения запроса над партиционированной версией таблицы ClickHouse сканирует и обрабатывает 671 блока строк (~ 5.5 миллиона строк) за 90 миллисекунд:
В то время как выполнения запроса над непартиционированной таблицей ClickHouse сканирует и обрабатывает 241 блока (~ 2 миллиона строк) за 12 миллисекунд: