Интеграция OpenTelemetry для сбора данных
Любое решение для мониторинга требует средства для сбора и экспорта логов и трасс. Для этой цели ClickHouse рекомендует проект OpenTelemetry (OTel).
"OpenTelemetry — это фреймворк и инструментарий для мониторинга, предназначенный для создания и управления телеметрическими данными, такими как трассы, метрики и логи."
В отличие от ClickHouse или Prometheus, OpenTelemetry не является бэкендом для мониторинга и скорее сосредоточен на генерации, сборе, управлении и экспорте телеметрических данных. Хотя первоначальная цель OpenTelemetry заключалась в том, чтобы позволить пользователям легко инструментировать свои приложения или системы с использованием специфичных для языка SDK, она расширилась, чтобы включать сбор логов через коллекционер OpenTelemetry — агент или прокси, который получает, обрабатывает и экспортирует телеметрические данные.
Компоненты, связанные с ClickHouse
OpenTelemetry состоит из нескольких компонентов. Кроме того, что он предоставляет спецификацию данных и API, стандартизированный протокол и соглашения о наименовании для полей/колонок, OTel предоставляет две возможности, которые являются основополагающими для создания решения мониторинга с ClickHouse:
- OpenTelemetry Collector — это прокси, который принимает, обрабатывает и экспортирует телеметрические данные. Решение на базе ClickHouse использует этот компонент как для сбора логов, так и для обработки событий перед их пакетированием и вставкой.
- Языковые SDK, которые реализуют спецификацию, API и экспорт телеметрических данных. Эти SDK эффективно обеспечивают правильную запись трасс в коде приложения, генерируя составные промежутки и обеспечивая передачу контекста между сервисами через метаданные, тем самым формируя распределенные трассы и обеспечивая корреляцию промежутков. Эти SDK дополняются экосистемой, которая автоматически реализует общие библиотеки и фреймворки, что означает, что пользователю не требуется изменять свой код и он получает инструментирование "из коробки".
Решение для мониторинга на базе ClickHouse использует оба этих инструмента.
Дистрибуции
У коллекционера OpenTelemetry есть несколько дистрибуций. Receiver filelog вместе с экспортёром ClickHouse, необходимым для решения на базе ClickHouse, присутствует только в OpenTelemetry Collector Contrib Distro.
Эта дистрибуция содержит множество компонентов и позволяет пользователям экспериментировать с различными конфигурациями. Однако при работе в производственной среде рекомендуется ограничить коллекционер только теми компонентами, которые необходимы для окружения. Некоторые причины для этого:
- Уменьшение размера коллекционера, сокращение времени развертывания для коллекционера
- Повышение безопасности коллекционера за счет уменьшения доступной поверхности атаки
Создание пользовательского коллекционера можно осуществить с помощью OpenTelemetry Collector Builder.
Приём данных с помощью OTel
Роли развертывания коллекционера
Для сбора логов и их вставки в ClickHouse мы рекомендуем использовать OpenTelemetry Collector. OpenTelemetry Collector может быть развернут в двух основных ролях:
- Агент - Экземпляры агента собирают данные на краю, например, на серверах или на узлах Kubernetes, или получают события непосредственно от приложений, инструментированных с помощью OpenTelemetry SDK. В последнем случае экземпляр агента работает вместе с приложением или на том же хосте, что и приложение (например, в роли sidecar или DaemonSet). Агенты могут отправлять свои данные непосредственно в ClickHouse или на экземпляр шлюза. В первом случае это называется шаблоном развертывания агента.
- Шлюз - Экземпляры шлюза предоставляют автономный сервис (например, развертывание в Kubernetes), обычно для каждого кластера, центра обработки данных или региона. Эти экземпляры принимают события от приложений (или других коллекционеров в роли агентов) через единую конечную точку OTLP. Обычно развертывается набор экземпляров шлюзов, с готовым балансировщиком нагрузки, который используется для распределения нагрузки между ними. Если все агенты и приложения отправляют свои сигналы на эту единую конечную точку, это часто называется шаблоном развертывания шлюза.
Ниже предполагается простой агент-коллекционер, отправляющий свои события напрямую в ClickHouse. Смотрите Масштабирование с помощью шлюзов для получения дополнительных деталей о использовании шлюзов и о том, когда они применимы.
Сбор логов
Основное преимущество использования коллекционера заключается в том, что он позволяет вашим сервисам быстро выгружать данные, оставляя коллекционеру заботу о дополнительной обработке, такой как повторные попытки, пакетирование, шифрование или даже фильтрация конфиденциальных данных.
Коллекционер использует термины receiver, processor и exporter для своих трех основных этапов обработки. Receivers используются для сбора данных и могут быть основаны на вытягивании или отправке. Processors предоставляют возможность выполнять преобразования и обогащение сообщений. Exporters отвечают за отправку данных на вспомогательный сервис. Хотя этот сервис, теоретически, может быть другим коллекционером, мы предполагаем, что все данные отправляются напрямую в ClickHouse для первоначального обсуждения ниже.
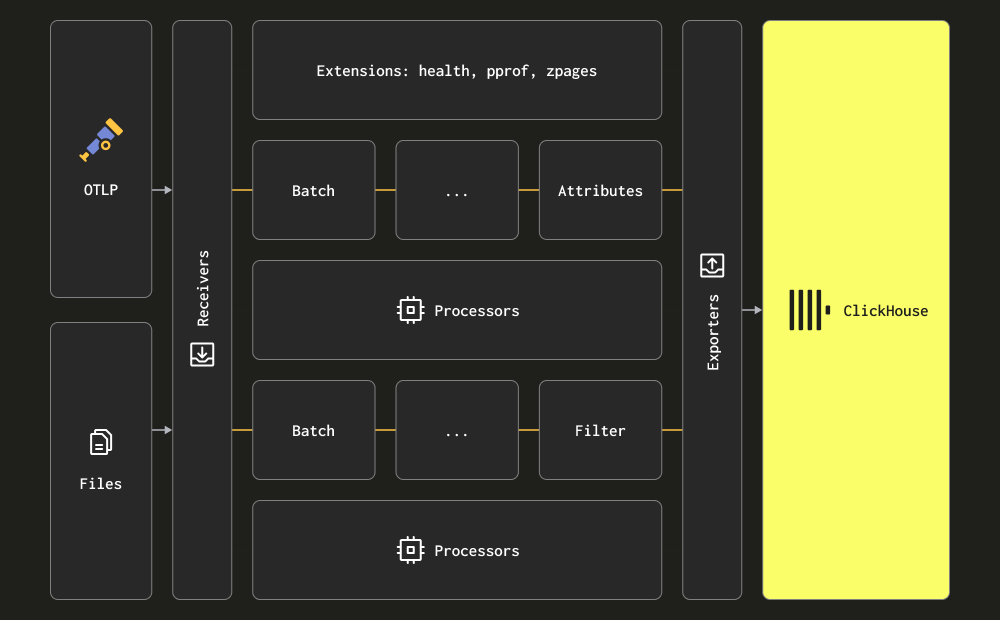
Мы рекомендуем пользователям ознакомиться с полным набором receivers, processors и exporters.
Коллекционер предоставляет два основных receiver для сбора логов:
Через OTLP - В этом случае логи отправляются (отправляются) прямо в коллекционер из OpenTelemetry SDK через протокол OTLP. Демо OpenTelemetry использует этот подход, экспортеры OTLP на каждом языке предполагают локальную конечную точку коллекционера. В этом случае коллекционер должен быть сконфигурирован с receiver OTLP — см. выше демо для конфигурации. Преимущество этого подхода заключается в том, что данные логов автоматически будут содержать Trace Id, позволяя пользователям позднее идентифицировать трассы для конкретного лога и наоборот.
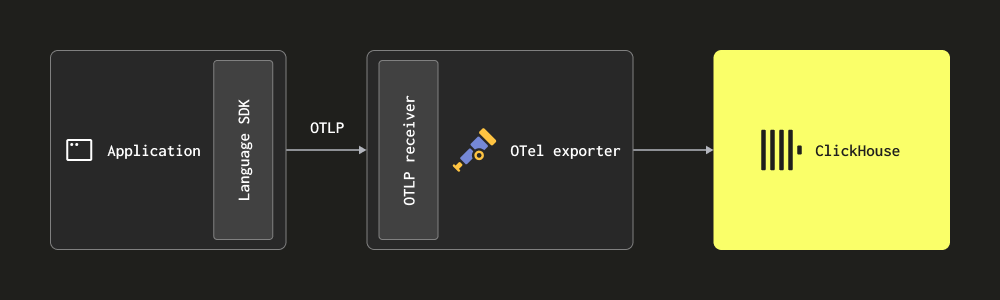
Этот подход требует от пользователей инструментария своего кода с помощью соответствующего языка SDK.
- Скрейпинг через receiver Filelog - Этот receiver отслеживает файлы на диске и формирует сообщения логов, отправляя их в ClickHouse. Этот receiver обрабатывает сложные задачи, такие как обнаружение многострочных сообщений, обработка прокрутки логов, контрольные точки для устойчивости к перезапуску и извлечение структуры. Этот receiver дополнительно может отслеживать логи контейнеров Docker и Kubernetes, развертываемых в виде helm-чарта, извлекая структуру из них и обогащая их деталями пода.
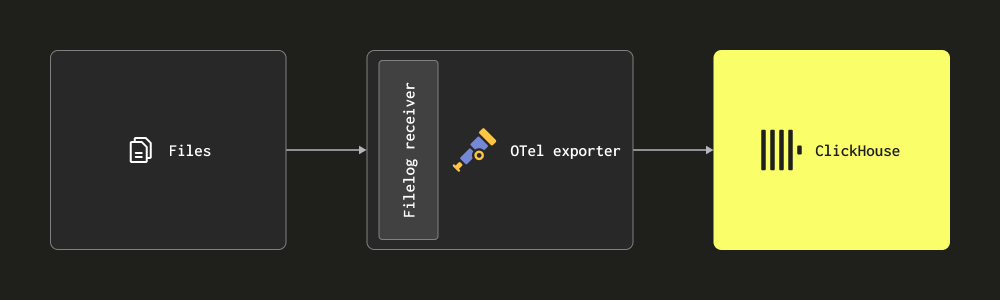
Большинство развертываний будут использовать комбинацию вышеуказанных receiver. Мы рекомендуем пользователям прочитать документацию коллекционера и ознакомиться с основными концепциями, а также структурой конфигурации и методами установки.
Структурированные и неструктурированные логи
Логи могут быть структурированными или неструктурированными.
Структурированный лог будет использовать формат данных, такой как JSON, определяя метаданные, такие как код http и IP-адрес источника.
Неструктурированные логи, хотя также обычно имеют некоторую внутреннюю структуру, извлекаемую через шаблон regex, будут представлять лог просто как строку.
Мы рекомендуем пользователям использовать структурированное логирование и записывать в JSON (т.е. ndjson), где это возможно. Это упростит необходимую обработку логов позже, либо перед отправкой в ClickHouse с помощью Processors коллекционера, либо во время вставки, используя материализованные представления. Структурированные логи в конечном итоге сэкономят ресурсы на последующей обработке, уменьшая необходимую производительность CPU в вашем решении на базе ClickHouse.
Пример
Для примеров мы предоставляем структурированный (JSON) и неструктурированный набор логов, каждый из которых содержит примерно 10 миллионов строк, доступных по следующим ссылкам:
Мы используем структурированный набор данных для примера ниже. Убедитесь, что этот файл загружен и извлечен, чтобы воспроизвести следующие примеры.
Следующее представляет собой простую конфигурацию для OTel Collector, который считывает эти файлы на диске, используя receiver filelog, и выводит полученные сообщения в stdout. Мы используем оператор json_parser, так как наши логи структурированы. Измените путь к файлу access-structured.log.
Ниже приведенный пример извлекает временную метку из лога. Это требует использования оператора json_parser, который преобразует всю строку лога в строку JSON, помещая результат в LogAttributes. Это может быть ресурсоемким и может быть выполнено более эффективно в ClickHouse - Извлечение структуры с помощью SQL. Эквивалентный неструктурированный пример, использующий regex_parser для достижения этого, можно найти здесь.
Пользователи могут следовать официальным инструкциям для локальной установки коллекционера. Важно убедиться, что инструкции изменены для использования дистрибуции contrib (которая содержит receiver filelog), т.е. вместо otelcol_0.102.1_darwin_arm64.tar.gz пользователи должны загрузить otelcol-contrib_0.102.1_darwin_arm64.tar.gz. Выпуски можно найти здесь.
После установки OTel Collector можно запустить следующими командами:
Предполагая использование структурированных логов, сообщения будут иметь следующую форму на выходе:
Выше представлено одно сообщение лога, созданное OTel collector. Мы будем загружать эти же сообщения в ClickHouse в следующих разделах.
Полная схема сообщений логов, вместе с дополнительными столбцами, которые могут присутствовать, если использовать другие receivers, поддерживается здесь. Мы настоятельно рекомендуем пользователям ознакомиться с этой схемой.
Ключевое здесь то, что сама строка лога хранится в виде строки в поле Body, но JSON был автоматически извлечен в поле Attributes благодаря оператору json_parser. Этот же оператор использовался для извлечения временной метки в соответствующий столбец Timestamp. Для рекомендаций по обработке логов с помощью OTel см. Обработка.
Операторы являются самым базовым элементом обработки логов. Каждый оператор выполняет единую ответственность, такую как чтение строк из файла или разбор JSON из поля. Операторы затем связываются в цепочку в конвейере, чтобы достичь желаемого результата.
Вышеуказанные сообщения не имеют поля TraceID или SpanID. Если они присутствуют, например, в случаях, когда пользователи реализуют распределенное трассирование, их можно извлечь из JSON с помощью тех же техник, показанных выше.
Пользователям, которым необходимо собирать локальные или Kubernetes файлы логов, мы рекомендуем ознакомиться с доступными параметрами конфигурации для receiver filelog и тем, как обрабатываются смещения и разбор многострочных логов.
Сбор логов Kubernetes
Для сбора логов Kubernetes мы рекомендуем руководство документации Open Telemetry. Рекомендуется использовать Kubernetes Attributes Processor для обогащения логов и метрик метаданными подов. Это может потенциально создать динамические метаданные, т.е. метки, хранящиеся в столбце ResourceAttributes. Currently, ClickHouse uses the type Map(String, String) для этого столбца. Смотрите Использование карт и Извлечение из карт для получения дополнительных сведений о работе с этим типом.
Сбор трасс
Для пользователей, желающих инструментировать свой код и собирать трассы, мы рекомендуем следовать официальной документации OTel.
Чтобы доставить события в ClickHouse, пользователи должны развернуть OTel collector для получения событий трасс по протоколу OTLP через соответствующий receiver. Демо OpenTelemetry предоставляет пример инструментирования каждого поддерживаемого языка и отправки событий к коллекционеру. Пример соответствующей конфигурации коллекционера, которая выводит события в stdout, представлен ниже:
Пример
Поскольку трассы должны приниматься через OTLP, мы используем инструмент telemetrygen для генерации данных трасс. Следуйте инструкциям здесь для установки.
Следующая конфигурация принимает события трасс на receiver OTLP перед их отправкой в stdout.
Запустите эту конфигурацию с помощью:
Отправьте события трасс в коллекционер через telemetrygen:
Это приведет к появлению сообщений трасс, подобных примеру ниже, выводимым в stdout:
Выше представлено одно сообщение трассы, созданное OTel collector. Мы будем загружать эти же сообщения в ClickHouse в следующих разделах.
Полная схема сообщений трасс поддерживается здесь. Мы настоятельно рекомендуем пользователям ознакомиться с этой схемой.
Обработка - фильтрация, преобразование и обогащение
Как показано в предыдущем примере установки временной метки для лог-события, пользователи неизбежно захотят фильтровать, преобразовывать и обогащать сообщения событий. Это можно достичь с помощью нескольких возможностей в OpenTelemetry:
-
Processors - Processors берут данные, собранные receivers, и модифицируют или преобразуют их перед отправкой экспортером. Processors применяются в порядке, установленном в разделе
processorsконфигурации коллекционера. Эти процессы необязательны, но минимальный набор обычно рекомендуется. При использовании OTel collector с ClickHouse мы рекомендуем ограничить processors до:- memory_limiter, который используется для предотвращения ситуаций с нехваткой памяти на коллекционере. См. Оценка ресурсов для получения рекомендаций.
- Любого процессора, который выполняет обогащение на основе контекста. Например, Kubernetes Attributes Processor позволяет автоматически устанавливать атрибуты ресурсов для промежутков, метрик и логов с метаданными k8s, т.е. обогащая события их идентификатором пода источника.
- Выборка с хвоста или головы при необходимости для трасс.
- Базовая фильтрация - отбрасывание событий, которые не нужны, если это не может быть сделано с помощью оператора (см. ниже).
- Пакетирование - необходимо при работе с ClickHouse, чтобы обеспечить отправку данных пакетами. См. "Экспорт в ClickHouse".
-
Операторы - Операторы предоставляют самую базовую единицу обработки, доступную на уровне receiver. Поддерживается базовый разбор, позволяя установить такие поля, как Severity и Timestamp. Поддерживается разбор JSON и regex, а также фильтрация событий и базовые преобразования. Мы рекомендуем выполнять фильтрацию событий здесь.
Мы рекомендуем пользователям избегать чрезмерной обработки событий с использованием операторов или трансформирующих процессоров. Это может повлечь за собой значительные затраты по памяти и вычислительным ресурсам, особенно при разборе JSON. Теоретически можно выполнить всю обработку в ClickHouse во время вставки с материализованными представлениями и столбцами, за некоторыми исключениями — в частности, обогащением, зависящим от контекста, т.е. добавлением метаданных k8s. Для получения дополнительной информации см. Извлечение структуры с помощью SQL.
Если обработка осуществляется с использованием OTel collector, мы рекомендуем выполнять преобразования на экземплярах шлюзов и минимизировать любые работы, выполняемые на экземплярах агентов. Это обеспечит минимальные ресурсы, необходимые агентам на краю, работающим на серверах. Обычно мы заметили, что пользователи только выполняют фильтрацию (для минимизации ненужного сетевого трафика), установку временных меток (через операторы) и обогащение, что требует наличия контекста в агенте. Например, если экземпляры шлюзов находятся в другом кластере Kubernetes, обогащение k8s должно произойти на уровне агента.
Пример
Следующая конфигурация демонстрирует сбор неструктурированного файла логов. Обратите внимание на использование операторов для извлечения структуры из строк логов (regex_parser) и фильтрации событий, наряду с процессором для пакетирования событий и ограничения использования памяти.
config-unstructured-logs-with-processor.yaml
Экспорт в ClickHouse
Экспортеры отправляют данные на один или несколько бэкендов или мест назначения. Экспортеры могут быть основаны на извлечении (pull) или отправке (push). Для отправки событий в ClickHouse пользователям потребуется использовать основанный на отправке экспортер ClickHouse.
Экспортер ClickHouse является частью OpenTelemetry Collector Contrib, а не основной дистрибуции. Пользователи могут использовать либо дистрибуцию contrib, либо создать свой собственный коллектор.
Полный файл конфигурации представлен ниже.
Обратите внимание на следующие ключевые настройки:
- pipelines - В приведенной выше конфигурации подчеркивается использование конвейеров, состоящих из набора приемников, процессоров и экспортеров для журналов и трасс.
- endpoint - Связь с ClickHouse настраивается через параметр
endpoint. Строка подключенияtcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1обеспечивает связь по протоколу TCP. Если пользователи предпочитают HTTP по причинам переключения трафика, измените эту строку подключения, как описано здесь. Полные детали подключения, с возможностью указать имя пользователя и пароль в этой строке подключения, описаны здесь.
Важно: Обратите внимание, что приведенная выше строка подключения включает как сжатие (lz4), так и асинхронные вставки. Мы рекомендуем всегда включать оба. См. Пакетная обработка для получения дополнительных сведений об асинхронных вставках. Сжатие всегда должно указываться и по умолчанию не будет включено в старых версиях экспортера.
- ttl - значение здесь определяет, как долго данные хранятся. Дополнительные сведения в разделе "Управление данными". Это следует указывать в виде временной единицы в часах, например, 72h. Мы отключаем TTL в приведенном ниже примере, так как наши данные датируются 2019 годом и будут немедленно удалены ClickHouse при вставке.
- traces_table_name и logs_table_name - определяют имя таблицы для журналов и трасс.
- create_schema - определяет, создаются ли таблицы с использованием схем по умолчанию при запуске. По умолчанию установлено в true для простоты начала работы. Пользователи должны установить это значение в false и определить свою собственную схему.
- database - целевая база данных.
- retry_on_failure - параметры, определяющие, следует ли пытаться выполнить повторную вставку неудачных пакетов.
- batch - процессор пакетов обеспечивает отправку событий в виде пакетов. Мы рекомендуем значение около 5000 с истечением времени 5s. То, что будет достигнуто раньше, запустит пакет для отправки в экспортер. Уменьшение этих значений означает более низкую задержку в конвейере с данными, доступными для запроса раньше, но это будет стоить большего количества соединений и пакетов, отправляемых в ClickHouse. Это не рекомендуется, если пользователи не используют асинхронные вставки, так как это может вызвать проблемы с слишком большим количеством частей в ClickHouse. Напротив, если пользователи используют асинхронные вставки, доступность данных для запроса также будет зависеть от настроек асинхронной вставки - хотя данные все равно будут отправлены из соединителя раньше. См. Пакетная обработка для получения дополнительных сведений.
- sending_queue - контролирует размер очереди отправки. Каждый элемент в очереди содержит пакет. Если эта очередь заполнена, например, из-за недоступности ClickHouse, но события продолжают поступать, пакеты будут отброшены.
Предполагая, что пользователи извлекли структурированный файл журнала и имеют локальный экземпляр ClickHouse, работающий с учетом аутентификации по умолчанию, пользователи могут запустить эту конфигурацию с помощью команды:
Чтобы отправить данные трассировки этому сборщику, выполните следующую команду, используя инструмент telemetrygen:
После запуска подтвердите наличие событий журнала с помощью простого запроса:
Схема по умолчанию
По умолчанию экспортер ClickHouse создает целевую таблицу журнала как для журналов, так и для трасс. Это можно отключить с помощью параметра create_schema. Кроме того, имена таблицы для журналов и трасс можно изменить с их значений по умолчанию otel_logs и otel_traces с помощью указанных выше настроек.
В схемах ниже мы предполагаем, что TTL был включен как 72h.
Схема по умолчанию для журналов показана ниже (otelcol-contrib v0.102.1):
Столбцы здесь соответствуют официальной спецификации OTel для журналов, задокументированной здесь.
Несколько важных замечаний по этой схеме:
- По умолчанию таблица разбивается на партиции по дате через
PARTITION BY toDate(Timestamp). Это обеспечивает эффективное удаление устаревших данных. - TTL устанавливается через
TTL toDateTime(Timestamp) + toIntervalDay(3)и соответствует значению, заданному в конфигурации сборщика.ttl_only_drop_parts=1означает, что удаляются только целые части, когда все содержащиеся строки истекли. Это более эффективно, чем удаление строк внутри частей, что требует дорогостоящего удаления. Мы рекомендуем всегда устанавливать это значение. См. Управление данными с помощью TTL для получения дополнительных сведений. - Таблица использует классический
движок MergeTree. Это рекомендуется для журналов и трасс и не должно требовать изменений. - Таблица упорядочена по
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId). Это означает, что запросы будут оптимизированы для фильтров поServiceName,SeverityText,TimestampиTraceId- более ранние столбцы в списке будут фильтроваться быстрее, чем более поздние, например фильтрация поServiceNameбудет значительно быстрее, чем фильтрация поTraceId. Пользователи должны модифицировать это упорядочение в соответствии со своими ожидаемыми паттернами доступа - см. Выбор первичного ключа. - Приведенная схема применяет
ZSTD(1)к столбцам. Это обеспечивает лучшее сжатие для журналов. Пользователи могут увеличить уровень сжатия ZSTD (выше значения по умолчанию 1) для лучшего сжатия, хотя это редко бывает выгодно. Увеличение этого значения приведет к большему использованию CPU во время вставки (при сжатии), хотя декомпрессия (и, следовательно, запросы) должны оставаться сопоставимыми. См. здесь для получения дополнительных сведений. Дополнительное дельта-кодирование применяется к Timestamp с целью уменьшения его размера на диске. - Обратите внимание, что
ResourceAttributes,LogAttributesиScopeAttributesявляются картами. Пользователи должны ознакомиться с различиями между ними. Для доступа к этим картам и оптимизации доступа к ключам внутри них см. Использование карт. - Большинство других типов здесь, например,
ServiceNameкак LowCardinality, оптимизированы. Обратите внимание, что Body, хотя и является JSON в наших примерах журналов, хранится как строка. - Фильтры Блума применяются к ключам и значениям карт, а также к столбцу Body. Эти фильтры направлены на улучшение времени запроса при доступе к этим столбцам, но обычно не требуются. См. Вторичные/индексы пропуска данных.
Снова, это будет соответствовать столбцам, соответствующим официальной спецификации OTel для трасс, задокументированной здесь. Схема здесь использует многие из тех же настроек, что и вышеуказанная схема журналов, с дополнительными столбцами Link, специфичными для спанов.
Мы рекомендуем пользователям отключить автоматическое создание схемы и создать свои таблицы вручную. Это позволяет модифицировать первичные и вторичные ключи, а также предоставляет возможность ввести дополнительные столбцы для оптимизации производительности запросов. Для получения дополнительных сведений см. Дизайн схемы.
Оптимизация вставок
Для достижения высокой производительности вставки при получении сильных гарантий согласованности пользователи должны следовать простым правилам при вставке данных наблюдаемости в ClickHouse через сборщик. С правильной конфигурацией сборщика OTel следование следующим правилам должно быть простым. Это также позволяет избежать распространенных проблем, с которыми пользователи сталкиваются при первом использовании ClickHouse.
Пакетная обработка
По умолчанию каждая вставка, отправленная в ClickHouse, вызывает немедленное создание части хранилища, содержащей данные из вставки вместе с другой метаинформацией, которую необходимо сохранить. Следовательно, отправка меньшего количества вставок с большим количеством данных по сравнению с отправкой большего количества вставок с меньшим количеством данных сократит количество необходимых записей. Мы рекомендуем вставлять данные достаточно большими пакетами, минимум по 1000 строк одновременно. Дополнительные сведения здесь.
По умолчанию вставки в ClickHouse являются синхронными и идемпотентными, если идентичны. Для таблиц из семейства движков MergeTree ClickHouse по умолчанию автоматически удаляет дубликаты вставок. Это означает, что вставки допускают такие случаи, как следующие:
- (1) Если узел, получающий данные, испытывает проблемы, запрос вставки истечет (или получит более конкретную ошибку) и не получит подтверждение.
- (2) Если данные были записаны узлом, но подтверждение не может быть возвращено отправителю запроса из-за сетевых сбоев, отправитель либо получит истечение времени, либо сетевую ошибку.
С точки зрения сборщика, (1) и (2) могут быть трудными для различия. Однако в обоих случаях неподтвержденная вставка может быть немедленно повторена. Если повторный запрос вставки содержит те же данные в том же порядке, ClickHouse автоматически игнорирует повторный запрос вставки, если (неподтвержденная) исходная вставка прошла успешно.
Мы рекомендуем пользователям использовать процессор пакетов, указанный в предыдущих конфигурациях, чтобы удовлетворять вышеуказанным требованиям. Это обеспечивает отправку вставок как последовательных пакетов строк, удовлетворяющих вышеприведенным требованиям. Если ожидается, что сборщик будет иметь высокую пропускную способность (событий в секунду), и по крайней мере 5000 событий могут быть отправлены в каждой вставке, это обычно единственная пакетная обработка, необходимая в конвейере. В этом случае сборщик будет сбрасывать пакеты до достижения timeout процесса пакетной обработки, что обеспечивает низкую задержку по всему конвейеру и постоянный размер пакетов.
Используйте асинхронные вставки
Обычно пользователи вынуждены отправлять более мелкие пакеты, когда пропускная способность сборщика низкая, но все равно ожидают, что данные достигнут ClickHouse в пределах минимальной задержки от начала до конца. В этом случае небольшие пакеты отправляются, когда истекает timeout процессора пакетов. Это может вызвать проблемы, и тогда требуются асинхронные вставки. Эта ситуация обычно возникает, когда сборщики в роли агента настроены на прямую отправку в ClickHouse. Шлюзы, действуя как агрегаторы, могут облегчить эту проблему - см. Масштабирование с помощью шлюзов.
Если нельзя гарантировать большие пакеты, пользователи могут делегировать пакетирование ClickHouse, используя Асинхронные вставки. При асинхронных вставках данные сначала вставляются в буфер, а затем записываются в хранилище базы данных позже или асинхронно.
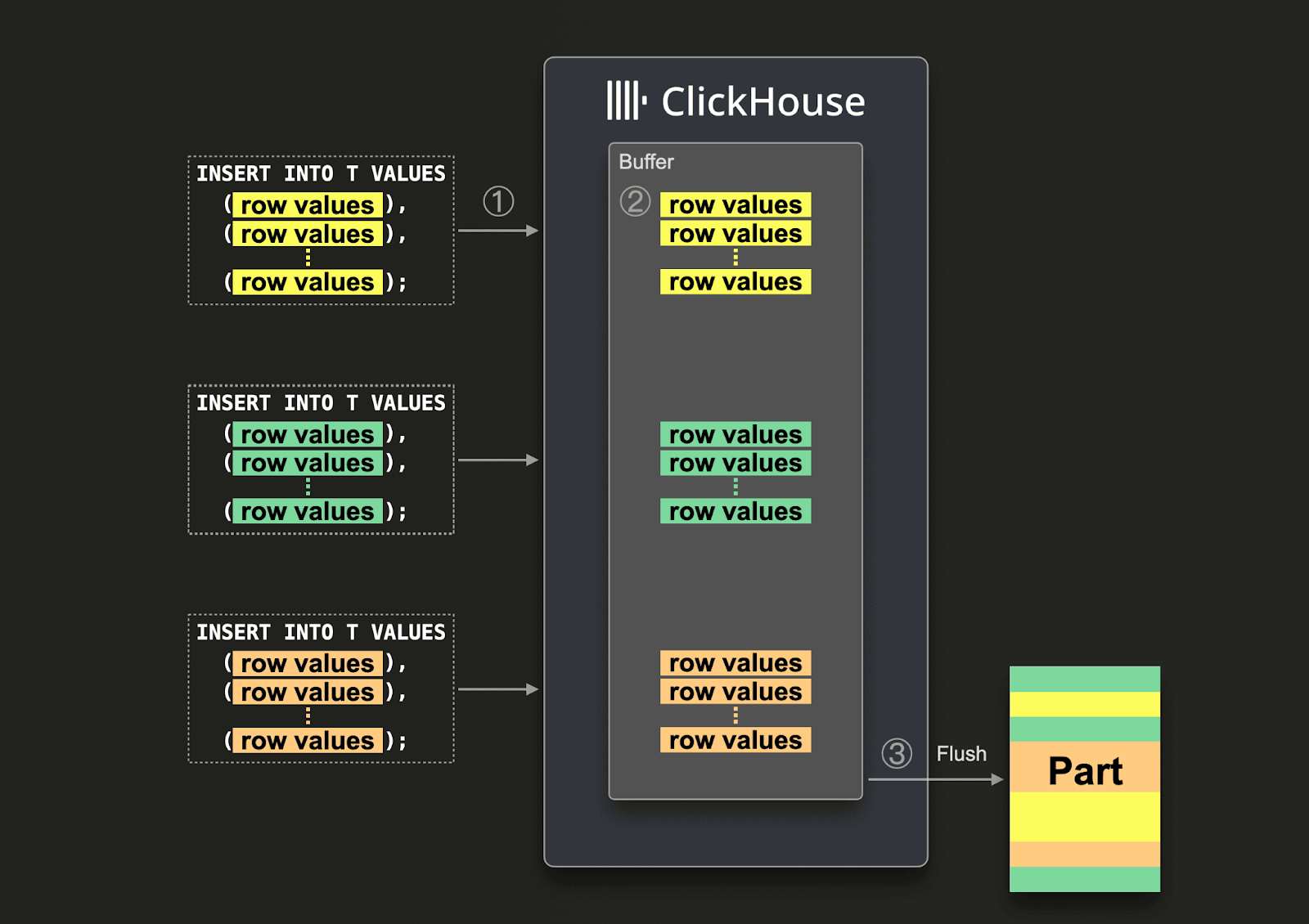
При включенных асинхронных вставках ситуации, когда ClickHouse ① получает запрос на вставку, данные запроса ② немедленно записываются сначала в буфер в памяти. Когда ③ происходит следующий сброс буфера, данные буфера упорядочиваются [/guides/best-practices/sparse-primary-indexes#data-is-stored-on-disk-ordered-by-primary-key-columns] и записываются как часть в хранилище базы данных. Обратите внимание, что данные не подлежат поиску через запросы до тех пор, пока они не будут сброшены в хранилище базы данных; сброс буфера [/optimize/asynchronous-inserts] может быть настраиваемым.
Чтобы включить асинхронные вставки для сборщика, добавьте async_insert=1 к строке подключения. Мы рекомендуем пользователям использовать wait_for_async_insert=1 (по умолчанию) для получения гарантий доставки - см. здесь для получения дополнительных сведений.
Данные из асинхронной вставки вставляются после сброса буфера ClickHouse. Это происходит либо после превышения async_insert_max_data_size, либо по истечении async_insert_busy_timeout_ms миллисекунд с момента первого запроса INSERT. Если async_insert_stale_timeout_ms установлено в ненулевое значение, данные вставляются после истечения времени async_insert_stale_timeout_ms миллисекунд с момента последнего запроса. Пользователи могут настроить эти параметры для контроля задержки от начала до конца их конвейера. Дополнительные настройки, которые могут быть использованы для настройки сброса буфера, задокументированы здесь. В целом, значения по умолчанию являются подходящими.
В случаях, когда используется низкое количество агентов с низкой пропускной способностью, но строгими требованиями к задержке от начала до конца, адаптивные асинхронные вставки могут быть полезны. В общем, они не применимы к случаям наблюдаемости с высокой пропускной способностью, как это видно с ClickHouse.
Наконец, поведение удаления дубликатов, связанное с синхронными вставками в ClickHouse, по умолчанию не включается при использовании асинхронных вставок. Если это необходимо, см. настройку async_insert_deduplicate.
Полные сведения о конфигурировании этой функции можно найти здесь, с глубоким погружением здесь.
Архитектуры развертывания
Существует несколько архитектур развертывания, возможных при использовании сборщика OTel с ClickHouse. Мы описываем каждую из них ниже и когда она, вероятно, будет актуальна.
Только агенты
В архитектуре только с агентами пользователи развертывают сборщик OTel в качестве агентов на краю сети. Эти агенты получают трассы от локальных приложений (например, в качестве контейнера sidecar) и собирают журналы с серверов и узлов Kubernetes. В этом режиме агенты отправляют свои данные непосредственно в ClickHouse.
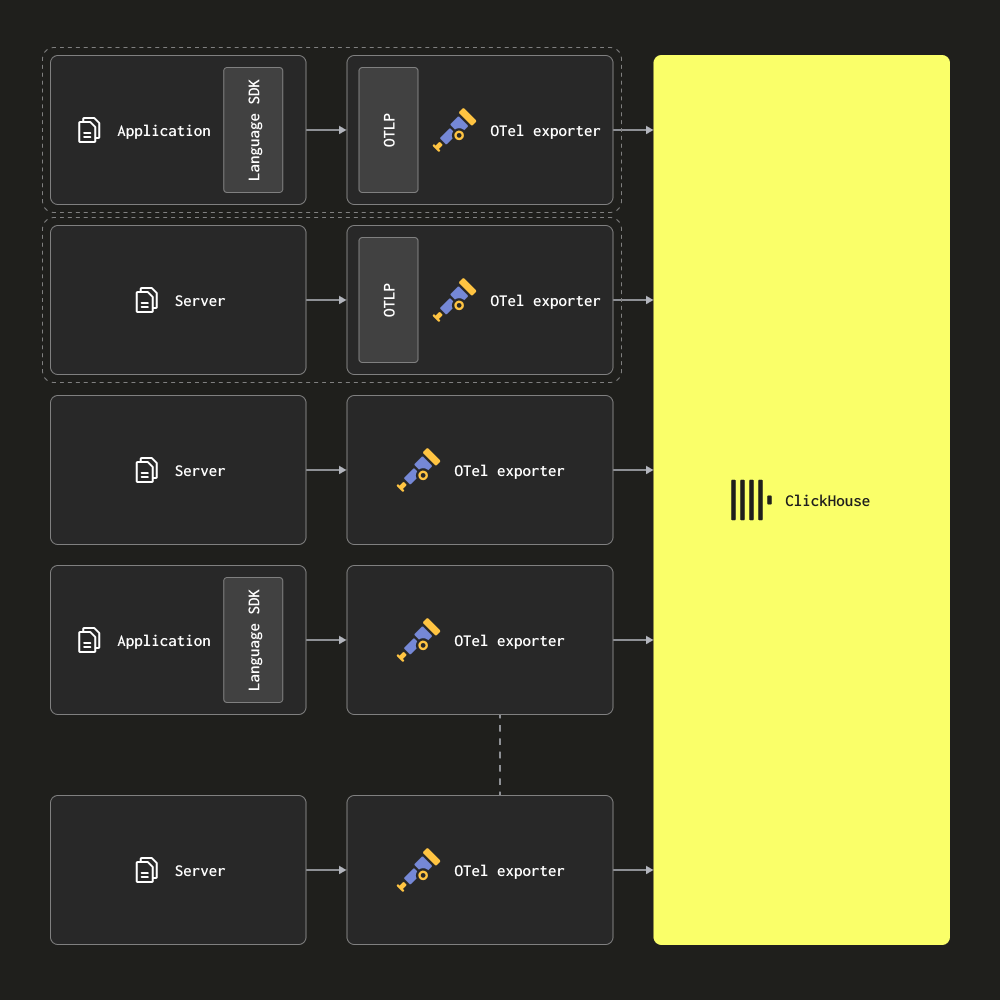
Эта архитектура подходит для небольших и средних развертываний. Ее основное преимущество заключается в том, что не требуется дополнительное оборудование, что позволяет минимизировать общий ресурсный след решения по наблюдаемости ClickHouse с простым сопоставлением между приложениями и сборщиками.
Пользователи должны рассмотреть возможность перехода на архитектуру, основанную на шлюзах, как только число агентов превысит несколько сотен. Эта архитектура имеет несколько недостатков, что делает ее сложной для масштабирования:
- Масштабирование соединений - Каждый агент устанавливает соединение с ClickHouse. Хотя ClickHouse способен поддерживать сотни (если не тысячи) одновременных соединений для вставки, это в конечном итоге станет ограничивающим фактором и сделает вставки менее эффективными - то есть ClickHouse будет использовать больше ресурсов для поддержания соединений. Использование шлюзов минимизирует количество соединений и делает вставки более эффективными.
- Обработка на краю - Любые преобразования или обработка событий должны производиться на краю или в ClickHouse в этой архитектуре. Это не только ограничивает, но и может означать сложные материализованные представления ClickHouse или перемещение значительных вычислений на край, где критические службы могут быть затронуты, а ресурсы ограничены.
- Малые пакеты и задержки - Агентские сборщики могут индивидуально собирать очень немного событий. Это обычно означает, что их необходимо настраивать на сброс с установленным интервалом для удовлетворения SLA по доставке. Это может привести к отправке небольших пакетов в ClickHouse сборщиком. Хотя это и недостаток, это может быть смягчено с помощью асинхронных вставок - см. Оптимизация вставок.
Масштабирование с помощью шлюзов
Коллекторы OTel могут быть развернуты в качестве экземпляров шлюзов для устранения вышеперечисленных ограничений. Они обеспечивают автономный сервис, обычно для каждого дата-центра или региона. Эти шлюзы принимают события от приложений (или других коллекторов в агентской роли) через единую конечную точку OTLP. Обычно разворачивается набор экземпляров шлюзов, с балансировщиком нагрузки, который используется для распределения нагрузки между ними.
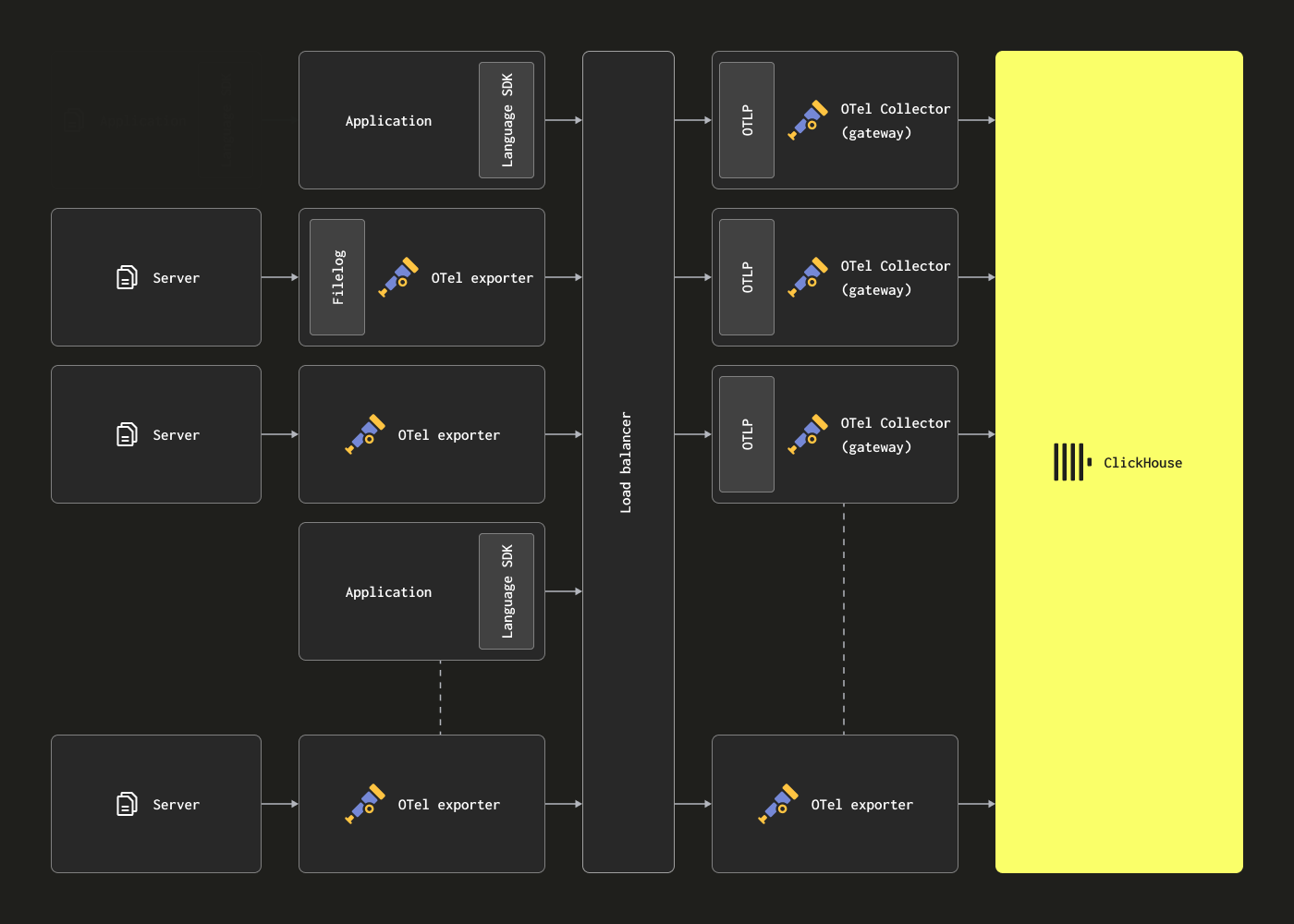
Цель этой архитектуры — разгрузить вычислительно интенсивную обработку от агентов, тем самым минимизируя их использование ресурсов. Эти шлюзы могут выполнять задачи преобразования, которые иначе должны были бы выполняться агентами. Более того, агрегируя события от многих агентов, шлюзы могут гарантировать, что большие пакеты отправляются в ClickHouse, позволяя эффективную вставку. Эти коллекторы шлюзов можно легко масштабировать по мере добавления большего количества агентов и увеличения пропускной способности событий. Пример конфигурации шлюза, с ассоциированной конфигурацией агента, потребляющего пример файла структурированного журнала, показан ниже. Обратите внимание на использование OTLP для связи между агентом и шлюзом.
clickhouse-gateway-config.yaml
Эти конфигурации можно запустить с помощью следующих команд.
Основной недостаток этой архитектуры заключается в связанных затратах и накладных расходах на управление набором коллекторов.
Для примера управления более крупными архитектурами на основе шлюзов с соответствующими уроками, мы рекомендуем эту статью в блоге.
Добавление Kafka
Читатели могут заметить, что вышеприведенные архитектуры не используют Kafka в качестве очереди сообщений.
Использование очереди Kafka в качестве буфера сообщений является популярным шаблоном проектирования, который встречается в архитектурах журналирования и был популяризирован стеком ELK. Это предоставляет несколько преимуществ; в первую очередь, это помогает обеспечить более сильные гарантии доставки сообщений и помогает справляться с обратным нажимом. Сообщения отправляются от агентов сбора данных в Kafka и записываются на диск. Теоретически кластеризированный экземпляр Kafka должен обеспечивать высокую пропускную способность буфера сообщений, поскольку для записи данных линейно на диск потребляется меньше вычислительных ресурсов, чем для разбора и обработки сообщения — например, в Elastic токенизация и индексация требуют значительных накладных расходов. Перемещая данные от агентов, вы также снижаете риск потери сообщений в результате ротации журналов на источнике. Наконец, это предлагает некоторые возможности повторной отправки сообщений и репликации между регионами, что может быть привлекательно для некоторых случаев использования.
Тем не менее, ClickHouse может обрабатывать вставку данных очень быстро — миллионы строк в секунду на умеренном оборудовании. Обратный нажим от ClickHouse редок. Часто внедрение очереди Kafka означает большую архитектурную сложность и затраты. Если вы можете принять принцип, что журналы не нуждаются в тех же гарантиях доставки, что и банковские транзакции и другие критически важные данные, мы рекомендуем избегать сложности Kafka.
Однако, если вам нужны высокие гарантии доставки или возможность повторной отправки данных (возможно, на несколько источников), Kafka может быть полезным архитектурным дополнением.
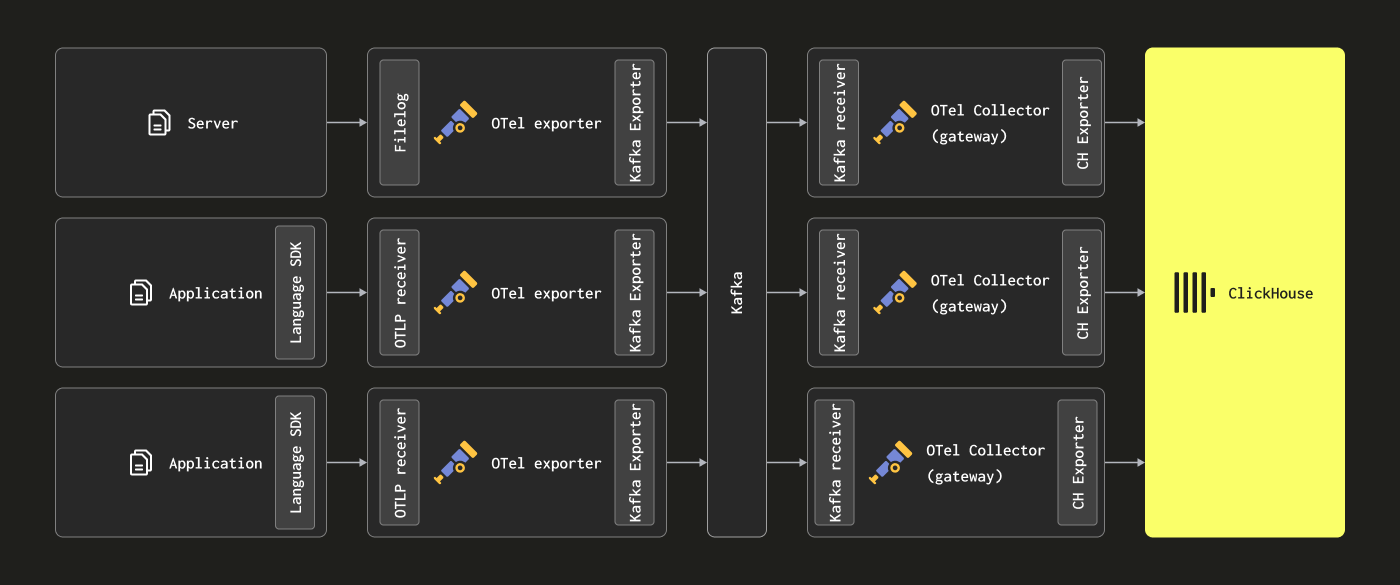
В этом случае агенты OTel могут быть настроены на отправку данных в Kafka через экспортер Kafka. Экземпляры шлюзов, в свою очередь, обрабатывают сообщения, используя приемник Kafka. Мы рекомендуем руководство Confluent и OTel для получения дополнительных сведений.
Оценка ресурсов
Требования к ресурсам для коллектора OTel будут зависеть от пропускной способности событий, размера сообщений и объема выполняемой обработки. Проект OpenTelemetry поддерживает бенчмарки, которые пользователи могут использовать для оценки требований к ресурсам.
На нашем опыте экземпляр шлюза с 3 ядрами и 12 ГБ ОЗУ может обрабатывать около 60k событий в секунду. Это предполагает минимальный конвейер обработки, ответственный за переименование полей и отсутствие регулярных выражений.
Для экземпляров агентов, отвечающих за отправку событий в шлюз и только устанавливающих временную метку на событии, мы рекомендуем пользователям ориентироваться на предполагаемое количество журналов в секунду. Следующие представляют собой приблизительные числа, которые пользователи могут использовать в качестве отправной точки:
| Скорость журналирования | Ресурсы для коллектора агента |
|---|---|
| 1k/секунда | 0.2CPU, 0.2GiB |
| 5k/секунда | 0.5 CPU, 0.5GiB |
| 10k/секунда | 1 CPU, 1GiB |