Миграция из BigQuery в ClickHouse Cloud
Почему использовать ClickHouse Cloud вместо BigQuery?
TLDR: Потому что ClickHouse быстрее, дешевле и мощнее, чем BigQuery для современных аналитических данных:

Загрузка данных из BigQuery в ClickHouse Cloud
Набор данных
В качестве примера набора данных для демонстрации типичной миграции из BigQuery в ClickHouse Cloud, мы используем набор данных Stack Overflow, задокументированный здесь. Это содержит каждый post, vote, user, comment и badge, которые произошли на Stack Overflow с 2008 года до апреля 2024 года. Схема BigQuery для этих данных показана ниже:

Для пользователей, которые хотят заполнить этот набор данных в экземпляре BigQuery, чтобы протестировать шаги миграции, мы предоставили данные для этих таблиц в формате Parquet в GCS bucket, а команды DDL для создания и загрузки таблиц в BigQuery доступны здесь.
Миграция данных
Миграция данных между BigQuery и ClickHouse Cloud делится на два основных типа рабочих нагрузок:
- Начальная массовая загрузка с периодическими обновлениями - Необходимо мигрировать начальный набор данных, а также периодические обновления через установленные интервалы, например, ежедневно. Обновления здесь обрабатываются повторной отправкой строк, которые изменились - определяемых по столбцу, который можно использовать для сравнений (например, по дате). Удаления обрабатываются с помощью полной периодической перезагрузки набора данных.
- Репликация в реальном времени или CDC - Должен быть мигрирован начальный набор данных. Изменения в этом наборе данных должны отражаться в ClickHouse почти в реальном времени, при допустимой задержке в несколько секунд. Это эффективно процесс Change Data Capture (CDC), при котором таблицы в BigQuery должны быть синхронизированы с ClickHouse, т.е. вставки, обновления и удаления в таблице BigQuery должны применяться к эквивалентной таблице в ClickHouse.
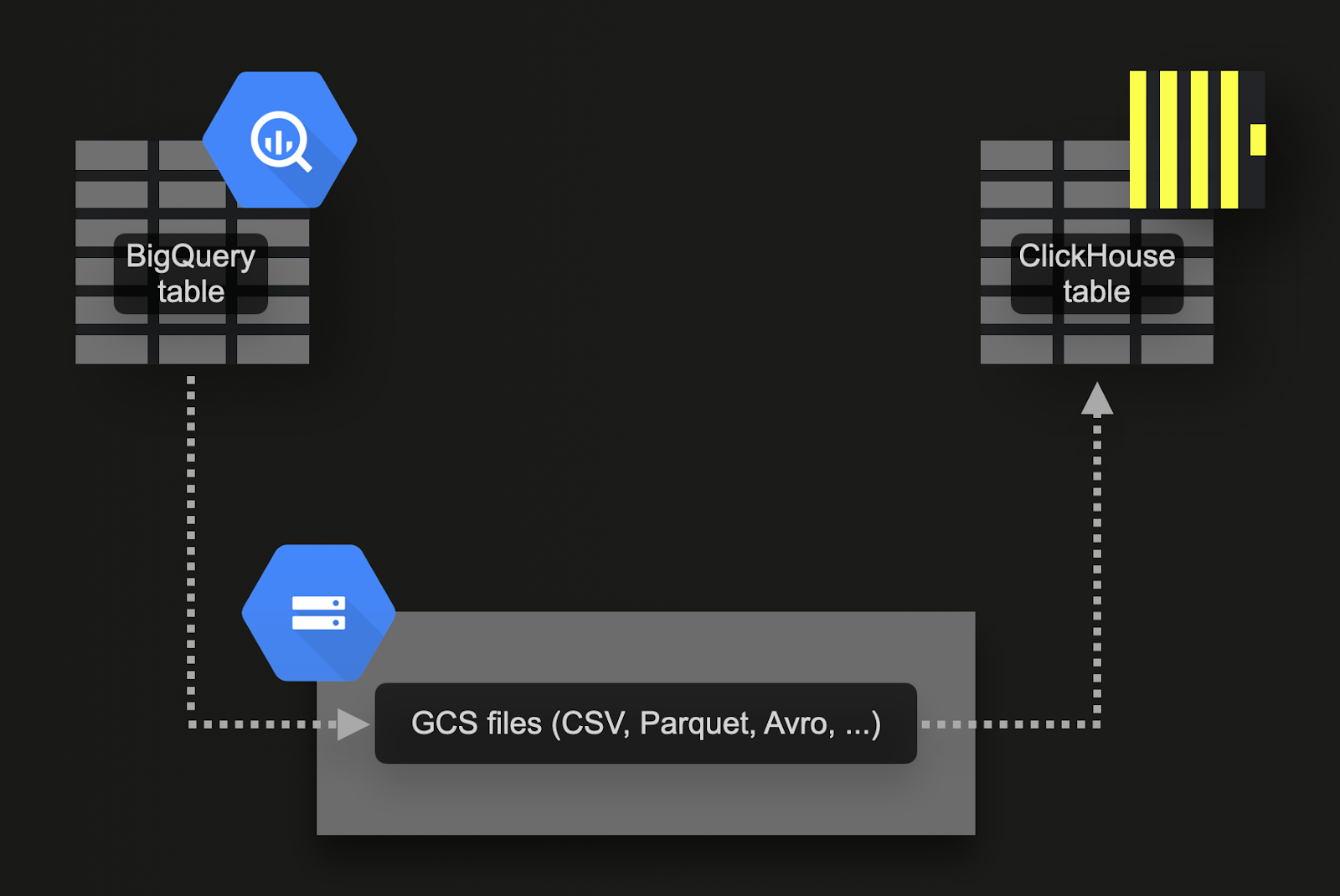
Массовая загрузка через Google Cloud Storage (GCS)
BigQuery поддерживает экспорт данных в объектное хранилище Google (GCS). Для нашего примера набора данных:
-
Экспортируйте 7 таблиц в GCS. Команды для этого доступны здесь.
-
Импортируйте данные в ClickHouse Cloud. Для этого мы можем использовать функцию таблицы gcs. DDL и запросы импорта доступны здесь. Обратите внимание, что поскольку экземпляр ClickHouse Cloud состоит из нескольких вычислительных узлов, вместо функции таблицы
gcs, мы используем функцию таблицы s3Cluster. Эта функция также работает с бакетами gcs и использует все узлы сервиса ClickHouse Cloud для загрузки данных параллельно.
Этот подход имеет ряд преимуществ:
- Функциональность экспорта BigQuery поддерживает фильтр для экспорта подмножества данных.
- BigQuery поддерживает экспорт в Parquet, Avro, JSON и CSV форматы и несколько типов сжатия - все поддерживаемые ClickHouse.
- GCS поддерживает управление жизненным циклом объектов, позволяя удалять данные, которые были экспортированы и импортированы в ClickHouse, после заданного времени.
- Google позволяет экспортировать до 50 ТБ в день в GCS бесплатно. Пользователи платят только за хранение в GCS.
- Экспорты автоматически создают несколько файлов, ограничивая каждый максимумом в 1 ГБ данных таблицы. Это полезно для ClickHouse, поскольку это позволяет оптимизировать импорты.
Перед тем, как пробовать следующие примеры, мы рекомендуем пользователям ознакомиться с разрешениями, необходимыми для экспорта и рекомендациями по локализации для максимизации производительности экспорта и импорта.
Репликация в реальном времени или CDC через запланированные запросы
Change Data Capture (CDC) - это процесс, с помощью которого таблицы поддерживаются синхронизированными между двумя базами данных. Это значительно усложняется, если обновления и удаления должны обрабатываться в почти реальном времени. Один из подходов - просто запланировать периодический экспорт, используя функциональность запланированных запросов BigQuery. Если вы можете принять некоторую задержку в данных, которые будут вставлены в ClickHouse, этот подход легко реализовать и поддерживать. Пример приведен в этом блоге.
Проектирование схем
Набор данных Stack Overflow содержит несколько связанных таблиц. Рекомендуем сосредоточиться на миграции основной таблицы в первую очередь. Это может не обязательно быть самой большой таблицей, а скорее той, на которую вы ожидаете получить наибольшее количество аналитических запросов. Это позволит вам ознакомиться с основными концепциями ClickHouse. Эта таблица может потребовать переработки по мере добавления дополнительных таблиц, чтобы полностью использовать функции ClickHouse и получить оптимальную производительность. Мы изучаем этот процесс моделирования в наших документах по моделированию данных.
Соблюдая этот принцип, мы сосредотачиваемся на основной таблице posts. Схема BigQuery для этого показана ниже:
Оптимизация типов
Применение процесса описанного здесь приводит к следующей схеме:
Мы можем заполнить эту таблицу с помощью простого INSERT INTO SELECT, читая экспортированные данные из gcs с использованием gcs функции таблицы. Обратите внимание, что в ClickHouse Cloud вы также можете использовать совместимую с gcs s3Cluster функцию таблицы, чтобы параллелить загрузку по нескольким узлам:
Мы не сохраняем никаких null в нашей новой схеме. Указанный выше вставляет их неявно в значения по умолчанию для их соответствующих типов - 0 для целых чисел и пустое значение для строк. ClickHouse также автоматически преобразует любые числовые значения в их целевую точность.
Чем первичные ключи ClickHouse отличаются?
Как описано здесь, как и в BigQuery, ClickHouse не обеспечивает уникальность значений столбца первичного ключа таблицы.
Подобно кластеризации в BigQuery, данные таблицы ClickHouse хранятся на диске в порядке расположения по столбцам первичного ключа. Этот порядок используется оптимизатором запросов для предотвращения повторной сортировки, минимизации использования памяти для соединений и обеспечения короткого замыкания для клаузул LIMIT. В отличие от BigQuery, ClickHouse автоматически создает разреженный первичный индекс на основе значений столбца первичного ключа. Этот индекс используется для ускорения всех запросов, содержащих фильтры по столбцам первичного ключа. В частности:
- Эффективность использования памяти и диска имеет первостепенное значение для масштаба, в котором ClickHouse часто используется. Данные записываются в таблицы ClickHouse партиями, известными как части, с применением правил для слияния этих частей в фоновом режиме. В ClickHouse каждая часть имеет свой собственный первичный индекс. Когда части сливаются, то первичные индексы также сливаются. Имейте в виду, что эти индексы не создаются для каждой строки. Вместо этого первичный индекс для части имеет одну индексную запись на группу строк - эта техника называется разреженным индексированием.
- Разреженное индексирование возможно, потому что ClickHouse хранит строки для части на диске в порядке, заданном определенным ключом. Вместо того, чтобы напрямую находить отдельные строки (как индекс на основе B-дерева), разреженный первичный индекс позволяет быстро (с помощью бинарного поиска по индексным записям) идентифицировать группы строк, которые могли бы соответствовать запросу. Найденные группы потенциально соответствующих строк затем параллельно передаются в движок ClickHouse для поиска совпадений. Этот дизайн индекса позволяет первичному индексу быть небольшим (он полностью помещается в основной памяти), при этом значительно ускоряя время выполнения запросов, особенно для диапазонных запросов, которые типичны для использования аналитических данных. Для получения более подробной информации мы рекомендуем это подробное руководство.
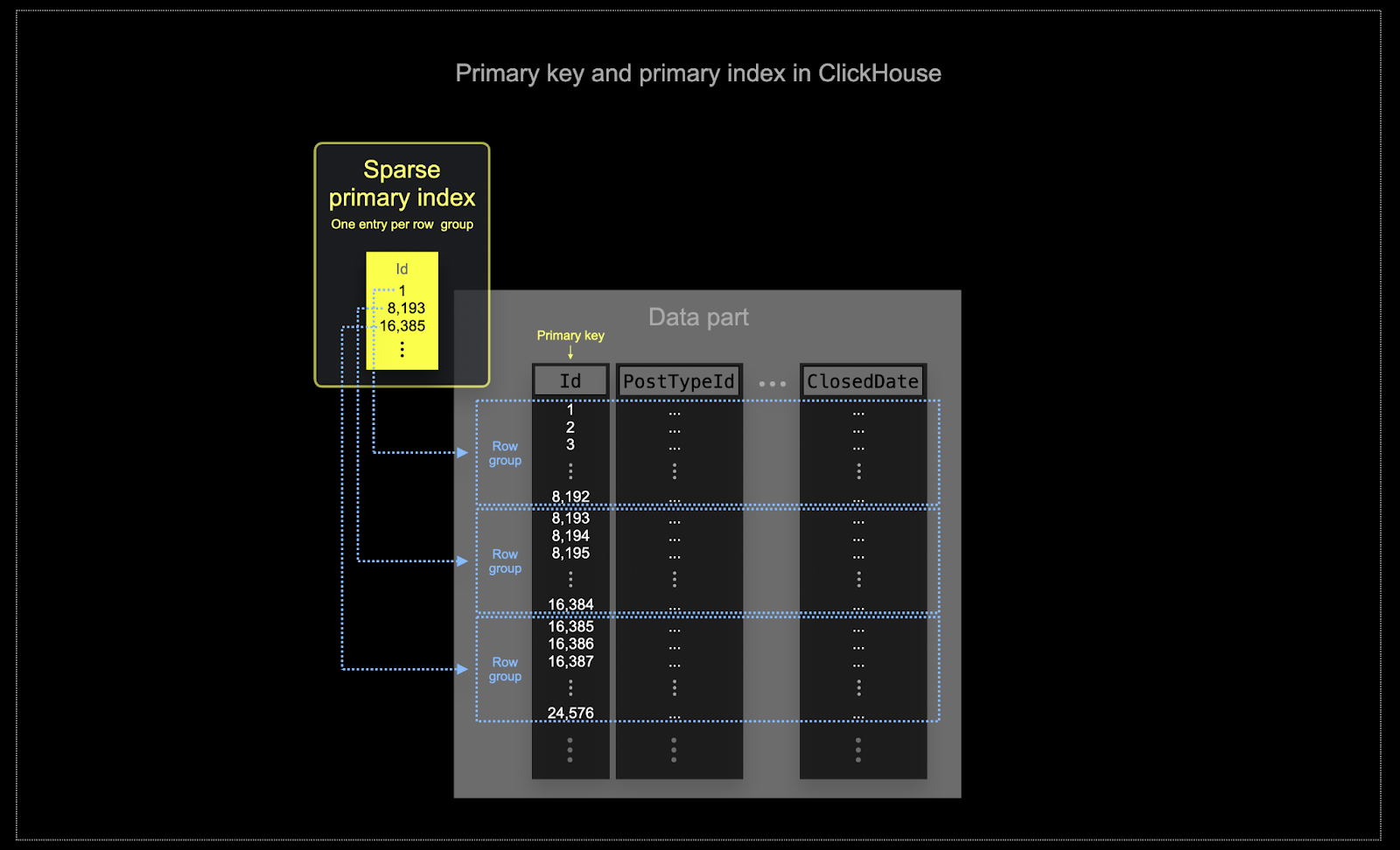
Выбранный первичный ключ в ClickHouse будет определять не только индекс, но и порядок, в котором данные записываются на диск. Из-за этого это может существенно повлиять на уровни сжатия, что, в свою очередь, может повлиять на производительность запросов. Ключ сортировки, который вызывает запись значений большинства столбцов в смежном порядке, позволит выбранному алгоритму сжатия (и кодекам) более эффективно сжимать данные.
Все столбцы в таблице будут отсортированы на основе значения указанного ключа сортировки, независимо от того, включены ли они в сам ключ. Например, если
CreationDateиспользуется как ключ, порядок значений во всех других столбцах будет соответствовать порядку значений в столбцеCreationDate. Можно указать несколько ключей сортировки - это будет упорядочено с той же семантикой, что и клаузулаORDER BYв запросеSELECT.
Выбор ключа сортировки
Для соображений и шагов по выбору ключа сортировки, используя таблицу постов в качестве примера, смотрите здесь.
Техники моделирования данных
Мы рекомендуем пользователям, мигрирующим из BigQuery, прочитать руководство по моделированию данных в ClickHouse. Этот справочник использует тот же набор данных Stack Overflow и исследует несколько подходов, используя функции ClickHouse.
Партиции
Пользователи BigQuery будут знакомы с концепцией партиционирования таблиц для повышения производительности и управляемости больших баз данных путем разделения таблиц на более мелкие, более управляемые части, называемые партициями. Это партиционирование можно достичь, используя либо диапазон на указанном столбце (например, даты), определенные списки или хэш на ключе. Это позволяет администраторам организовывать данные на основе определенных критериев, таких как диапазоны дат или географические местоположения.
Партиционирование помогает улучшить производительность запросов, позволяя более быстрый доступ к данным через отбор партиций и более эффективное индексирование. Это также помогает выполнять задачи обслуживания, такие как резервное копирование и очистка данных, позволяя выполнять операции на отдельных партициях, а не на всей таблице. Кроме того, партиционирование может значительно улучшить масштабируемость баз данных BigQuery, распределяя нагрузку между несколькими партициями.
В ClickHouse партиционирование указывается в таблице при ее первоначальном определении через клаузу PARTITION BY. Эта клаузула может содержать SQL-выражение по любому столбцу или столбцам, результаты которого определят, в какую партицию отправляется строка.
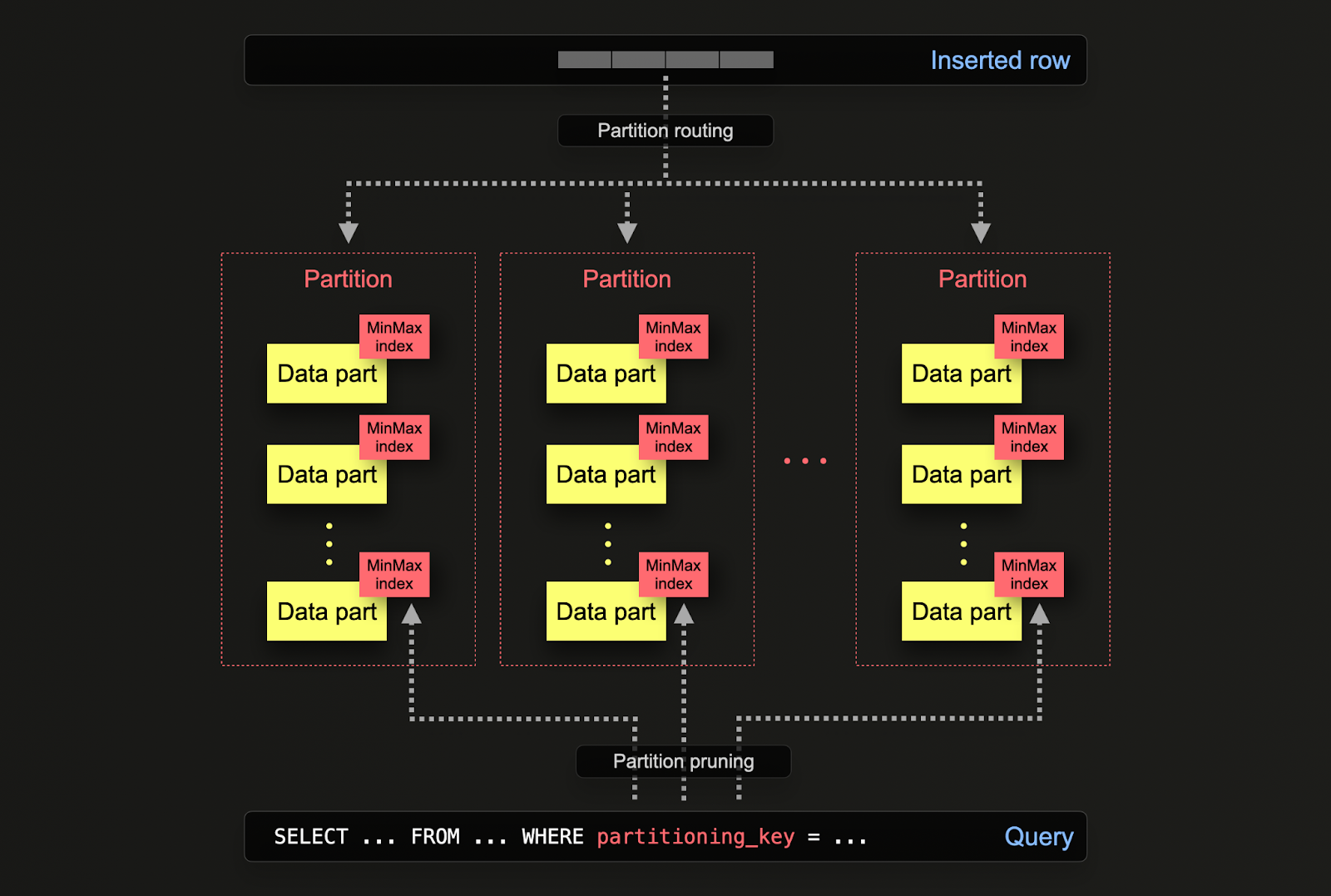
Части данных логически связаны с каждой партицией на диске и могут запрашиваться в изоляции. Для примера ниже мы партиционируем таблицу постов по годам, используя выражение toYear(CreationDate). По мере вставки строк в ClickHouse это выражение будет оцениваться для каждой строки - строки затем маршрутизируются к результирующей партиции в виде новых частей данных, принадлежащих этой партиции.
Применения
Партиционирование в ClickHouse имеет аналогичные применения, как и в BigQuery, но с некоторыми тонкими различиями. Более конкретно:
- Управление данными - В ClickHouse пользователи должны в первую очередь рассматривать партиционирование как функцию управления данными, а не как технику оптимизации запросов. Отделяя данные логически на основе ключа, каждая партиция может обрабатываться независимо, например, удаляться. Это позволяет пользователям эффективно перемещать партиции, а значит, подмножества, между уровнями хранения по времени или истекать данные/эффективно удалять из кластера. Например, ниже мы удаляем посты 2008 года:
- Оптимизация запросов - Хотя партиции могут помочь с производительностью запросов, это сильно зависит от паттернов доступа. Если запросы нацелены только на несколько партиций (в идеале одну), производительность может потенциально улучшиться. Это обычно полезно только в том случае, если ключ партиционирования не входит в первичный ключ и вы фильтруете по нему. Однако запросы, которые охватывают много партиций, могут иметь меньшую производительность, чем если бы партиционирование не использовалось (так как может быть больше частей в результате партиционирования). Преимущество нацеливания на одну партицию будет еще менее выраженным, если ключ партиционирования уже является ранним входом в первичный ключ. Партиционирование также можно использовать для оптимизации запросов
GROUP BY, если значения в каждой партиции уникальны. Однако в общем пользователи должны убедиться, что первичный ключ оптимизирован и только в исключительных случаях рассматривать партиционирование как технику оптимизации запросов, когда паттерны доступа охватывают конкретное предсказуемое подмножество дня, например, партиционирование по дням, когда большинство запросов - в последний день.
Рекомендации
Пользователи должны рассматривать партиционирование как технику управления данными. Это идеально, когда данные необходимо удалить из кластера для работы с временными рядами, например, старую партицию можно просто удалить.
Важно: убедитесь, что ваше выражение ключа партиционирования не приводит к высококардинальному набору, т.е. следует избегать создания более 100 партиций. Например, не партиционируйте свои данные по столбцам с высокой кардинальностью, таким как идентификаторы клиентов или имена. Вместо этого сделайте идентификатор клиента или имя первым столбцом в выражении ORDER BY.
Внутри ClickHouse создаются части для вставленных данных. По мере вставки данных количество частей увеличивается. Чтобы предотвратить чрезмерно высокое количество частей, что снизит производительность запросов (из-за большего количества файлов для чтения), части объединяются в фоновом асинхронном процессе. Если количество частей превышает предварительно настроенный лимит, то ClickHouse выдает исключение при вставке с ошибкой "слишком много частей". Это не должно происходить в нормальной работе и происходит только в случае неправильной настройки ClickHouse или неправильного его использования, например, при большом количестве мелких вставок. Поскольку части создаются для каждой партиции в изоляции, увеличение числа партиций приводит к увеличению числа частей, т.е. это кратное число партиций. Поэтому ключи партиционирования с высокой кардинальностью могут вызывать эту ошибку и должны быть избегаемы.
Материализованные представления против проекций
Концепция проекций в ClickHouse позволяет пользователям задавать несколько клауз ORDER BY для таблицы.
В моделировании данных ClickHouse мы исследуем, как материализованные представления могут использоваться в ClickHouse для предварительного вычисления агрегатов, преобразования строк и оптимизации запросов для различных паттернов доступа. Для последнего мы предоставили пример, где материализованное представление отправляет строки в целевую таблицу с другим ключом сортировки, чем у оригинальной таблицы, получающей вставки.
Например, рассмотрим следующий запрос:
Этот запрос требует сканирования всех 90 млн строк (хотя и быстро), поскольку UserId не является ключом сортировки. Ранее мы решили эту задачу, используя материалаизованное представление, действующее как справочник для PostId. Ту же проблему можно решить с помощью проекции. Команда ниже добавляет проекцию для ORDER BY user_id.
Обратите внимание, что сначала мы должны создать проекцию, а затем материализовать ее. Эта последняя команда приводит к тому, что данные хранятся дважды на диске в двух разных порядках. Проекция также может быть определена при создании данных, как показано ниже, и будет автоматически поддерживаться по мере вставки данных.
Если проекция создается через команду ALTER, создание происходит асинхронно, когда команда MATERIALIZE PROJECTION исполняется. Пользователи могут подтвердить прогресс этой операции с помощью следующего запроса, ожидая is_done=1.
Если мы повторим приведенный выше запрос, мы увидим, что производительность значительно улучшилась за счет дополнительного хранения.
С помощью команды EXPLAIN мы также подтверждаем, что проекция использовалась для обслуживания этого запроса:
Когда использовать проекции
Проекции являются привлекательной функцией для новых пользователей, поскольку они автоматически поддерживаются по мере вставки данных. Более того, запросы могут просто отправляться в одну таблицу, где проекции используются, где это возможно, чтобы сократить время отклика.
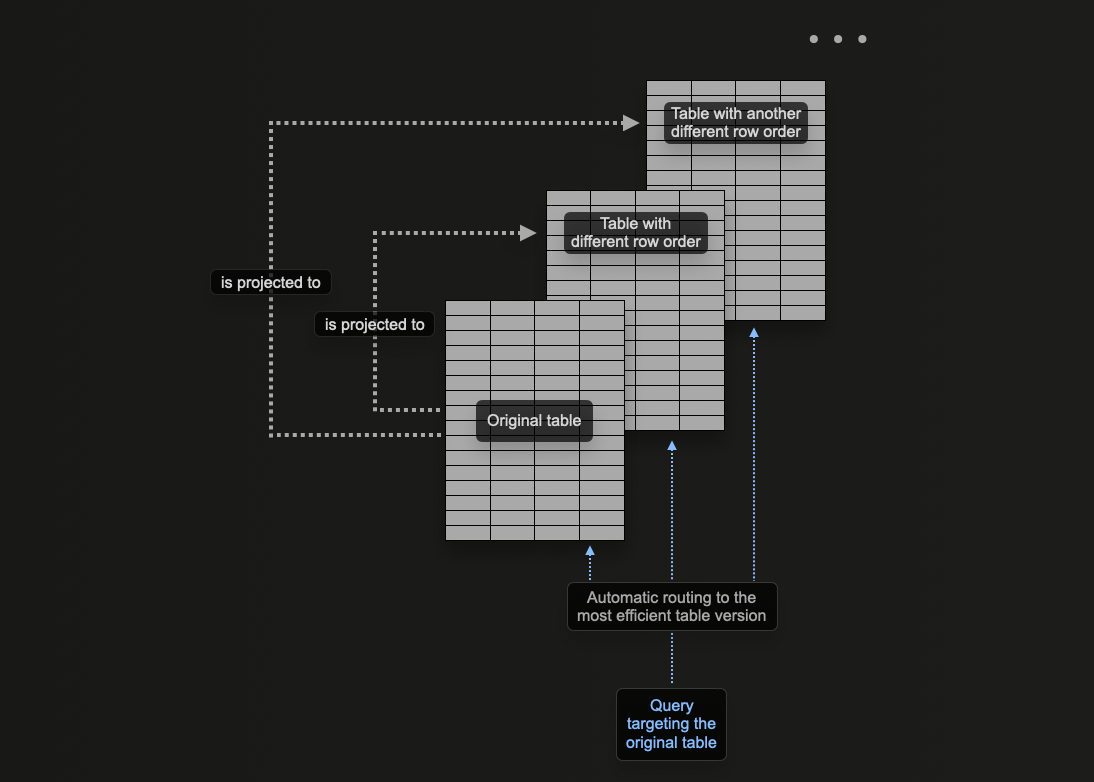
Это контрастирует с материализованными представлениями, где пользователю необходимо выбрать соответствующую оптимизированную целевую таблицу или переписать свой запрос, в зависимости от фильтров. Это увеличивает акцент на приложениях пользователей и усложняет клиентскую сторону.
Несмотря на эти преимущества, проекции имеют некоторые присущие ограничения, о которых пользователи должны знать и поэтому должны использоваться осторожно:
- Проекции не позволяют использовать разные TTL для исходной таблицы и (скрытой) целевой таблицы. Материализованные представления допускают разные TTL.
- Проекции в настоящее время не поддерживают
optimize_read_in_orderдля (скрытой) целевой таблицы. - Легковесные обновления и удаления не поддерживаются для таблиц с проекциями.
- Материализованные представления могут быть цепочками: целевая таблица одного материализованного представления может быть исходной таблицей другого материализованного представления и так далее. Это невозможно с проекциями.
- Проекции не поддерживают соединения; материализованные представления поддерживают.
- Проекции не поддерживают фильтры (клаузу
WHERE); материализованные представления поддерживают.
Мы рекомендуем использовать проекции, когда:
- Требуется полная переупорядочивание данных. Хотя выражение в проекции может, в теории, использовать
GROUP BY, материализованные представления более эффективны для поддержки агрегатов. Оптимизатор запросов также с большей вероятностью воспользуется проекциями, которые используют простое переупорядочивание, т.е.SELECT * ORDER BY x. Пользователи могут выбрать подмножество столбцов в этом выражении, чтобы уменьшить объем хранимой информации. - Пользователи комфортно воспринимают увеличение объема хранения и накладные расходы на дважды запись данных. Проверьте влияние на скорость вставки и оцените накладные расходы на хранение.
Переписывание запросов BigQuery в ClickHouse
Следующее предоставляет примеры запросов, сравнивающих BigQuery и ClickHouse. Этот список направлен на демонстрацию того, как использовать функции ClickHouse для значительного упрощения запросов. Примеры здесь используют полный набор данных Stack Overflow (до апреля 2024 года).
Пользователи (с более чем 10 вопросами), получающие наибольшее количество просмотров:
BigQuery
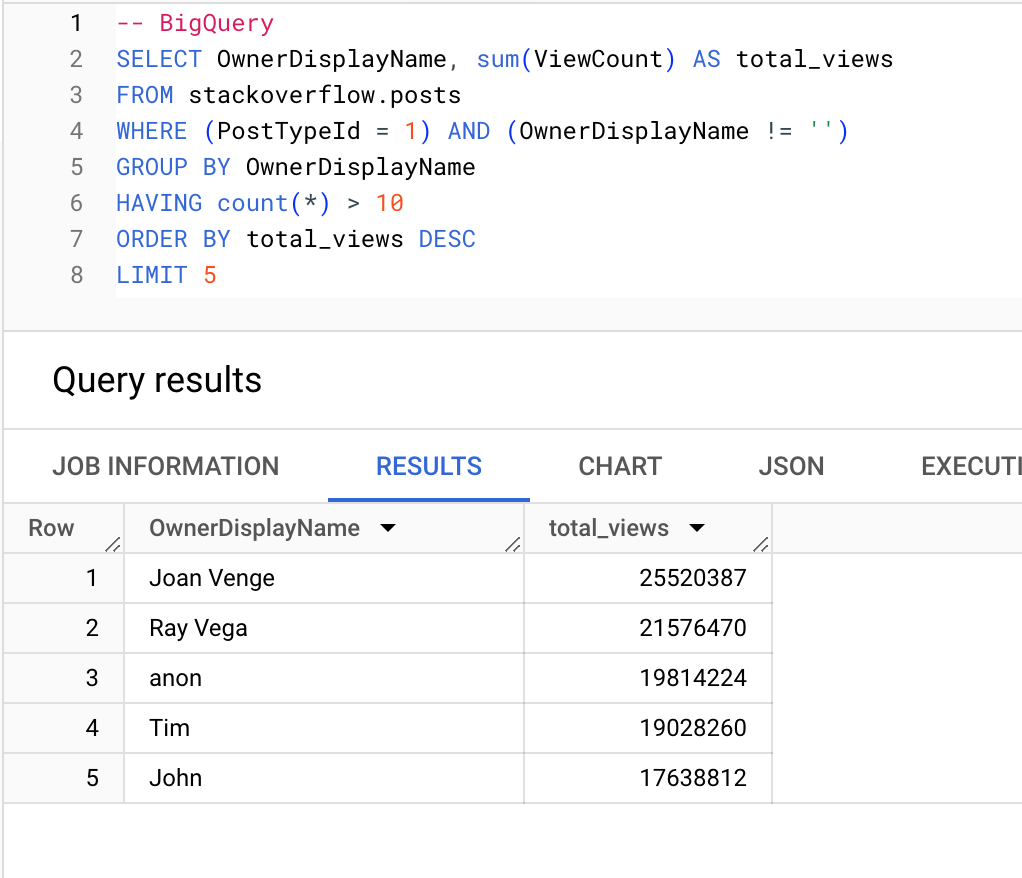
ClickHouse
Какие теги получают наибольшее количество просмотров:
BigQuery
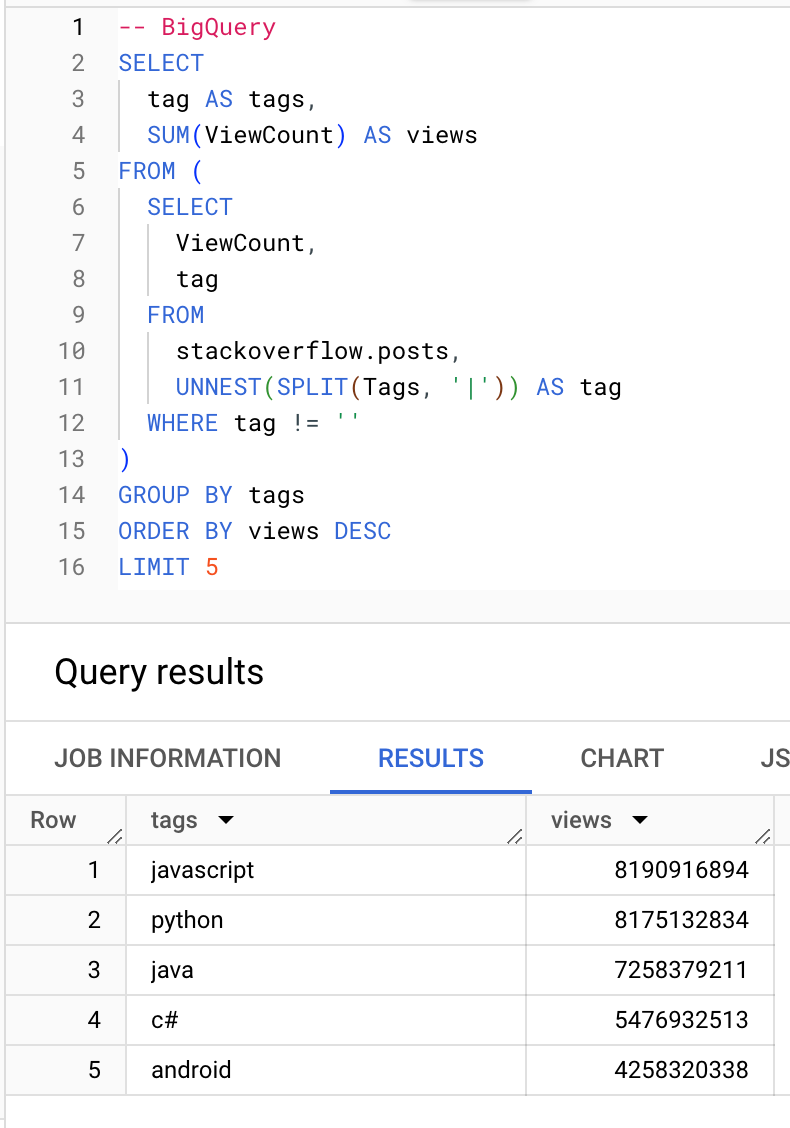
ClickHouse
Агрегатные функции
Где это возможно, пользователи должны использовать агрегатные функции ClickHouse. Ниже мы показываем использование argMax функции для вычисления самого просматриваемого вопроса каждого года.
BigQuery
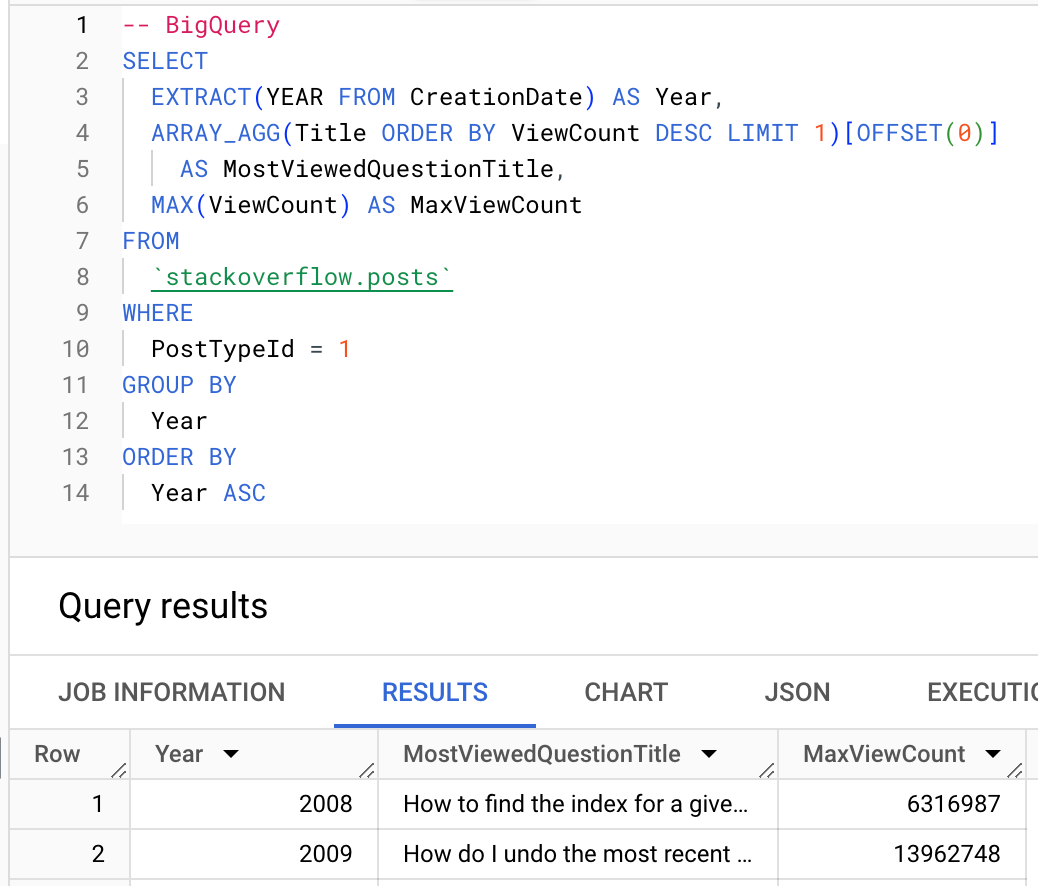

ClickHouse
Условные выражения и массивы
Условные и массивные функции значительно упрощают запросы. Следующий запрос вычисляет теги (с более чем 10000 вхождениями) с наибольшим процентным увеличением с 2022 по 2023 год. Обратите внимание, как следующий запрос ClickHouse лаконичен благодаря условным выражениям, массивным функциям и возможности повторного использования алиасов в предложениях HAVING и SELECT.
BigQuery
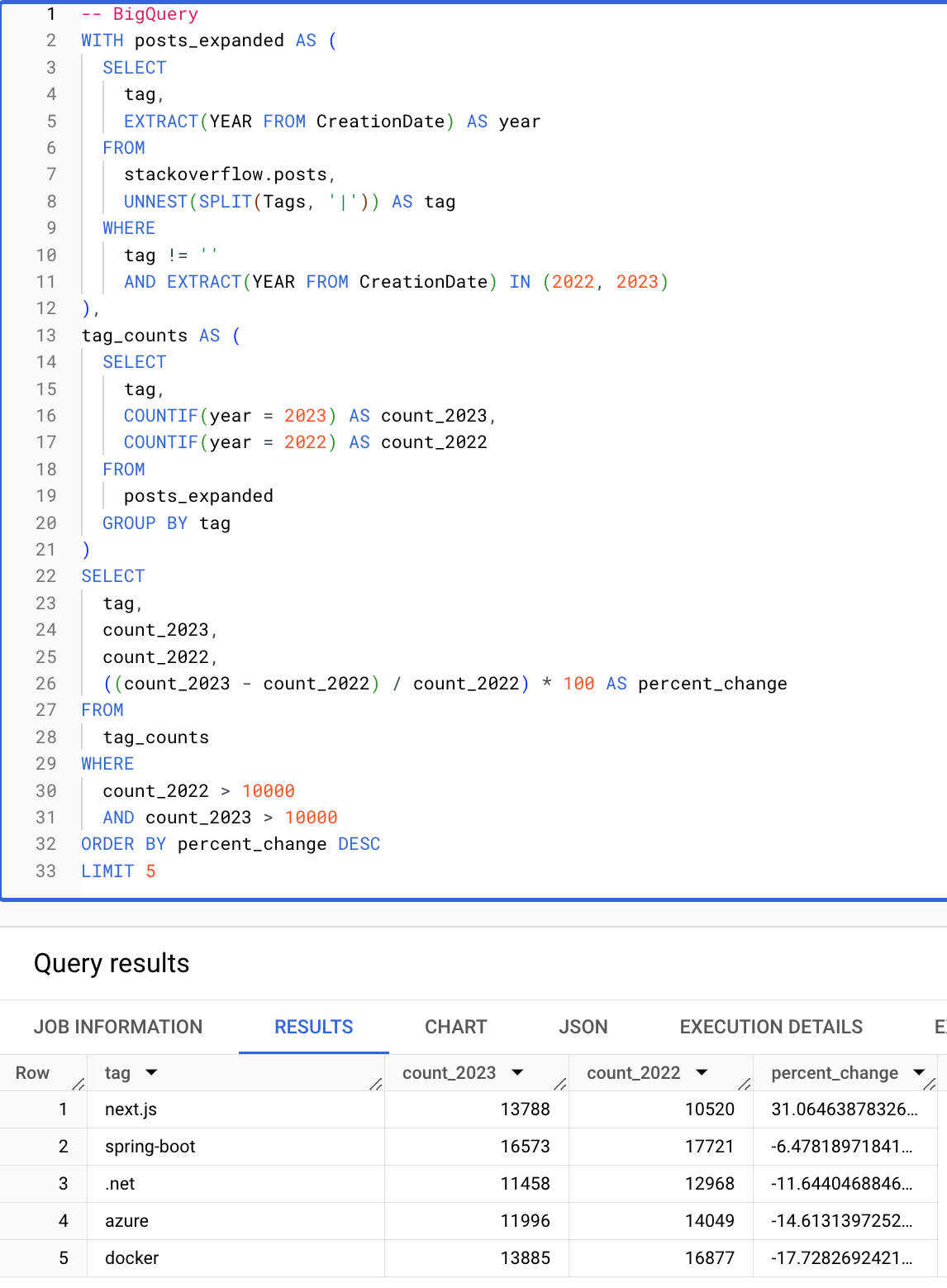
ClickHouse
Это завершает наше основное руководство для пользователей, переходящих с BigQuery на ClickHouse. Мы рекомендуем пользователям, мигрирующим с BigQuery, прочитать руководство по моделированию данных в ClickHouse, чтобы узнать больше о расширенных функциях ClickHouse.