Автоматическое масштабирование
Масштабирование — это возможность регулировки доступных ресурсов для удовлетворения потребностей клиентов. Услуги уровней Scale и Enterprise (с стандартным профилем 1:4) могут масштабироваться горизонтально с помощью программного вызова API или изменения настроек в пользовательском интерфейсе для корректировки системных ресурсов. В качестве альтернативы, эти услуги могут быть автоматически масштабированы вертикально для удовлетворения потребностей приложения.
Автоматическое вертикальное масштабирование is available in the Scale and Enterprise plans. To upgrade, visit the Plans page in the cloud console.
Как работает масштабирование в ClickHouse Cloud
В настоящее время ClickHouse Cloud поддерживает вертикальное автоматическое масштабирование и ручное горизонтальное масштабирование для услуг уровней Scale.
Для услуг уровня Enterprise масштабирование осуществляется следующим образом:
- Горизонтальное масштабирование: Ручное горизонтальное масштабирование будет доступно для всех стандартных и пользовательских профилей на уровне enterprise.
- Вертикальное масштабирование:
- Стандартные профили (1:4) будут поддерживать вертикальное автоматическое масштабирование.
- Пользовательские профили не будут поддерживать вертикальное автоматическое масштабирование или ручное вертикальное масштабирование при запуске. Однако эти услуги могут быть вертикально масштабированы, обратившись в службу поддержки.
Мы вводим новый механизм вертикального масштабирования для вычислительных реплик, который мы называем "Make Before Break" (MBB). Этот подход добавляет одну или несколько реплик нового размера перед удалением старых реплик, предотвращая любую потерю мощности во время операций масштабирования. Устранение разрыва между удалением существующих реплик и добавлением новых создает более бесшовный и менее разрушительный процесс масштабирования. Это особенно полезно в сценариях масштабирования вверх, где высокая загрузка ресурсов вызывает необходимость в дополнительной мощности, так как преждевременное удаление реплик лишь усугубит нагрузку на ресурсы.
Пожалуйста, обратите внимание, что в рамках этого изменения исторические данные системной таблицы будут храниться в течение максимального срока в 30 дней в рамках событий масштабирования. Кроме того, любые данные системной таблицы старше 19 декабря 2024 года для услуг на AWS или GCP и старше 14 января 2025 года для услуг на Azure не будут храниться в рамках миграции на новые организационные уровни.
Вертикальное автоматическое масштабирование
Автоматическое вертикальное масштабирование is available in the Scale and Enterprise plans. To upgrade, visit the Plans page in the cloud console.
Услуги Scale и Enterprise поддерживают автоматическое масштабирование на основе использования CPU и памяти. Мы постоянно отслеживаем историческое использование услуги в течение окна просмотра (протяженностью 30 часов), чтобы принимать решения о масштабировании. Если использование превышает или падает ниже определенных порогов, мы масштабируем услугу соответствующим образом для удовлетворения потребностей.
Автоматическое масштабирование на основе CPU вступает в силу, когда загрузка CPU пересекает верхний порог в диапазоне 50-75% (фактический порог зависит от размера кластера). В этот момент выделение CPU для кластера удваивается. Если использование CPU падает ниже половины верхнего порога (например, до 25% в случае 50% верхнего порога), выделение CPU сокращается вдвое.
Автоматическое масштабирование на основе памяти масштабирует кластер до 125% от максимального использования памяти или до 150%, если возникают ошибки OOM (недостаточно памяти).
Выбирается большее из рекоммендаций по CPU или памяти, и выделение CPU и памяти для услуги масштабируется с шагом в 1 CPU и 4 GiB памяти.
Настройка вертикального автоматического масштабирования
Масштабирование служб ClickHouse Cloud Scale или Enterprise может быть настроено членами организации с ролью Admin. Чтобы настроить вертикальное автоматическое масштабирование, перейдите на вкладку Настройки для вашей услуги и отрегулируйте минимальную и максимальную память, а также настройки CPU, как показано ниже.
Услуги с одной репликой не могут быть масштабированы для всех уровней.
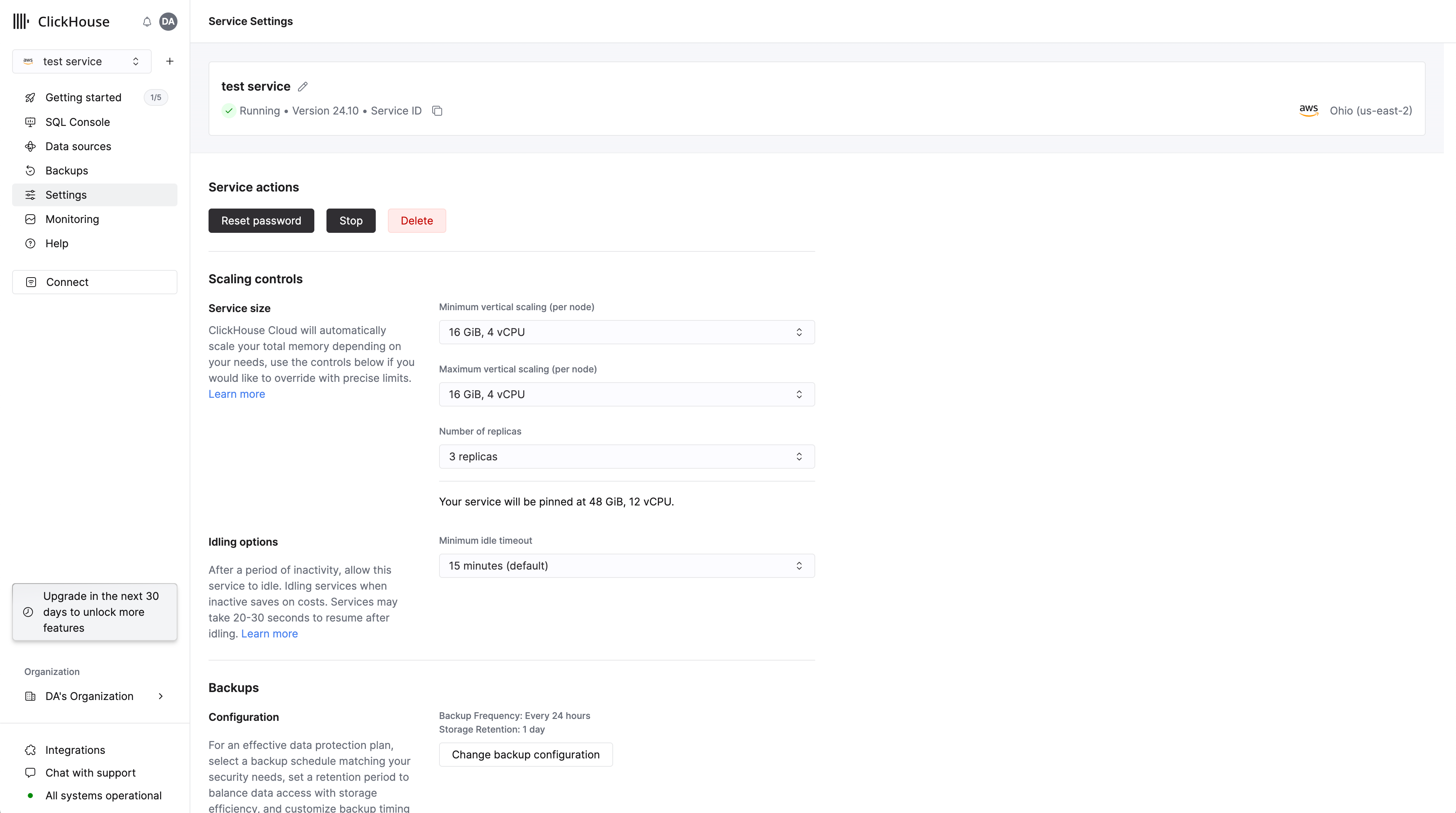
Установите Максимальную память для ваших реплик на более высокое значение, чем Минимальная память. Услуга затем будет масштабироваться по мере необходимости в рамках этих границ. Эти настройки также доступны во время первоначального создания услуги. Каждой реплике в вашей услуге будет выделено одинаковое количество памяти и ресурсов CPU.
Вы также можете установить эти значения одинаковыми, фактически "закрепляя" услугу на конкретной конфигурации. Это немедленно заставит услугу масштабироваться до желаемого размера, который вы выбрали.
Важно отметить, что это отключит все автоматическое масштабирование на кластере, и ваша услуга не будет защищена от увеличения использования CPU или памяти свыше этих настроек.
Для услуг уровня Enterprise стандартные профили 1:4 будут поддерживать вертикальное автоматическое масштабирование. Пользовательские профили не будут поддерживать вертикальное автоматическое масштабирование или ручное вертикальное масштабирование при запуске. Однако эти услуги могут быть вертикально масштабированы, обратившись в службу поддержки.
Ручное горизонтальное масштабирование
Ручное горизонтальное масштабирование is available in the Scale and Enterprise plans. To upgrade, visit the Plans page in the cloud console.
Вы можете использовать публичные API ClickHouse Cloud public APIs для масштабирования вашей службы, обновив настройки масштабирования для услуги или отрегулировав количество реплик из облачной консоли.
Scale и Enterprise уровни поддерживают услуги с одной репликой. Однако услуга в этих уровнях, которая начинается с нескольких реплик или масштабируется до множества реплик, может быть уменьшена до минимума в 2 реплики.
Услуги могут масштабироваться горизонтально до максимума 20 реплик. Если вам нужно больше реплик, пожалуйста, свяжитесь с нашей службой поддержки.
Горизонтальное масштабирование через API
Чтобы горизонтально масштабировать кластер, выполните запрос PATCH через API, чтобы отрегулировать количество реплик. Снимки экрана ниже показывают API-вызов для масштабирования кластера с 3 репликами до 6 реплик, и соответствующий ответ.
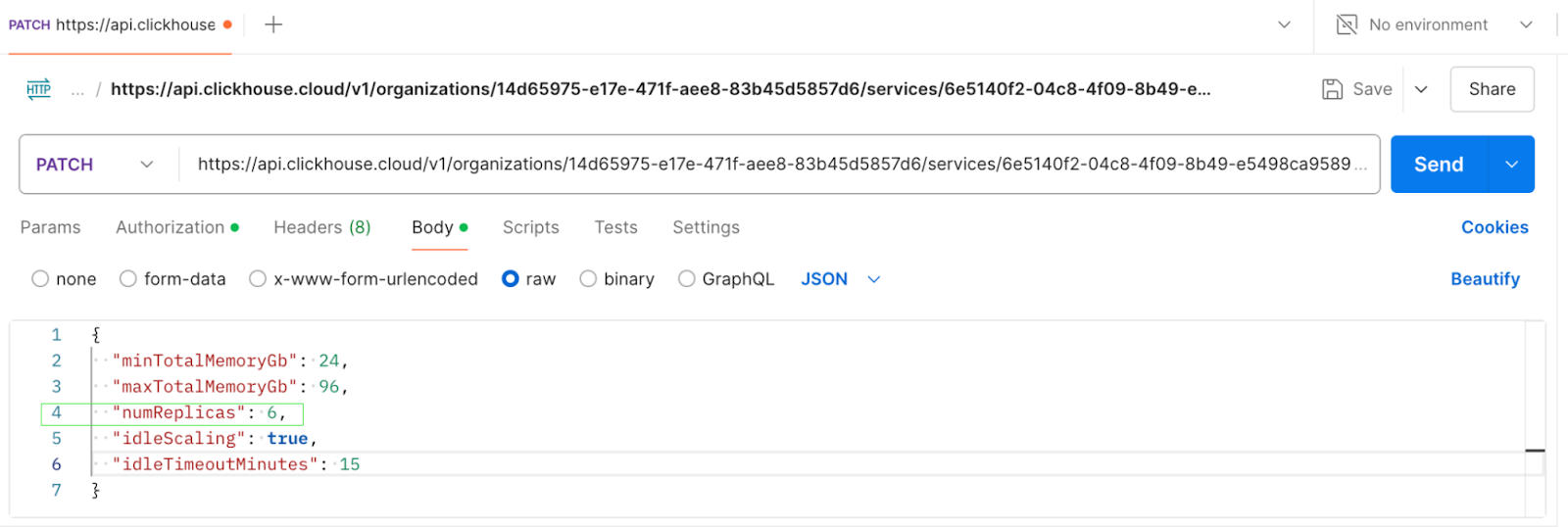
Запрос PATCH для обновления numReplicas
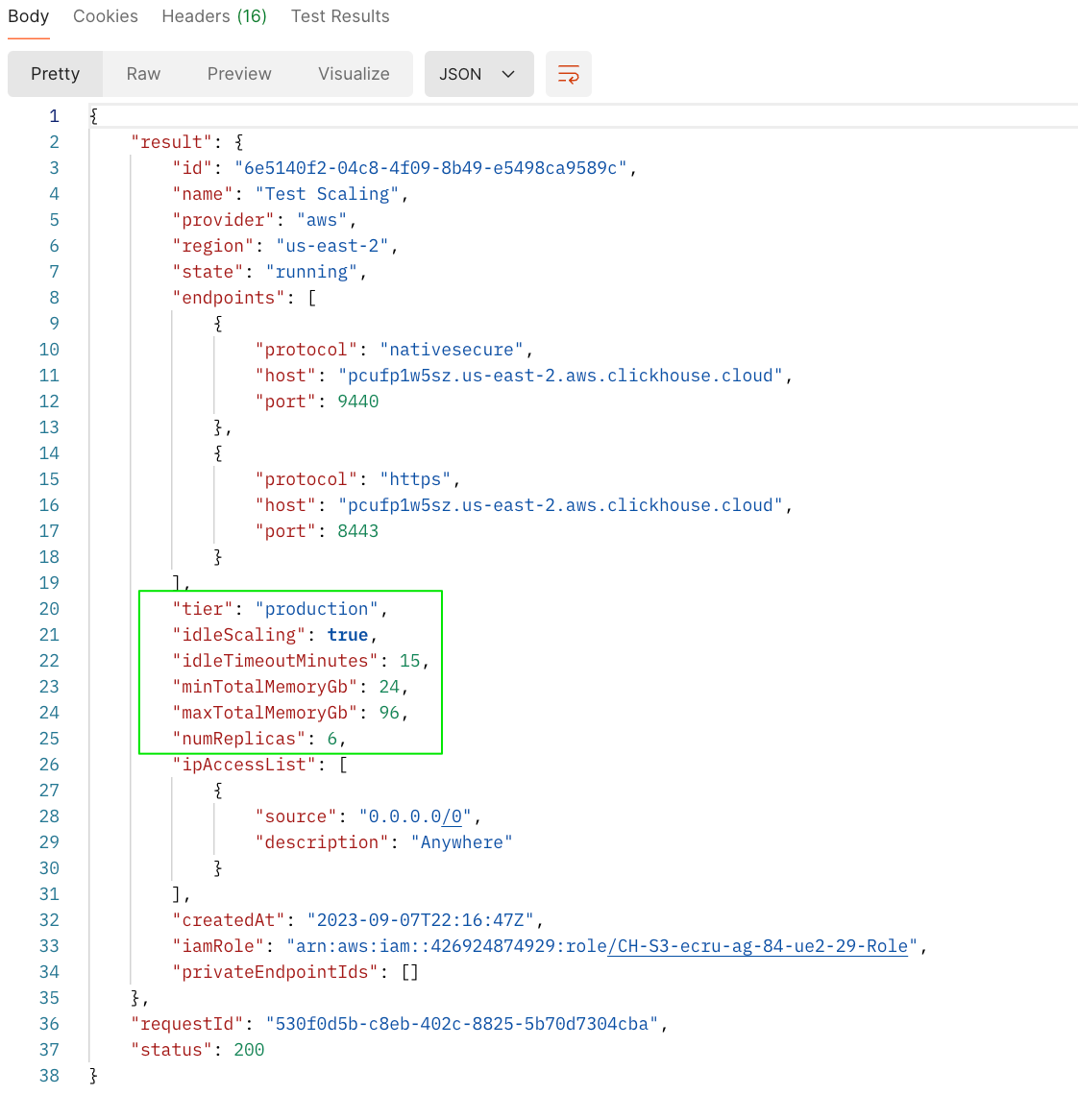
Ответ на запрос PATCH
Если вы выполните новый запрос на масштабирование или несколько запросов подряд, пока один из них уже в процессе, служба масштабирования проигнорирует промежуточные состояния и дойдет до окончательного количества реплик.
Горизонтальное масштабирование через UI
Чтобы масштабировать услугу горизонтально через интерфейс, вы можете отрегулировать количество реплик для услуги на странице Настройки.
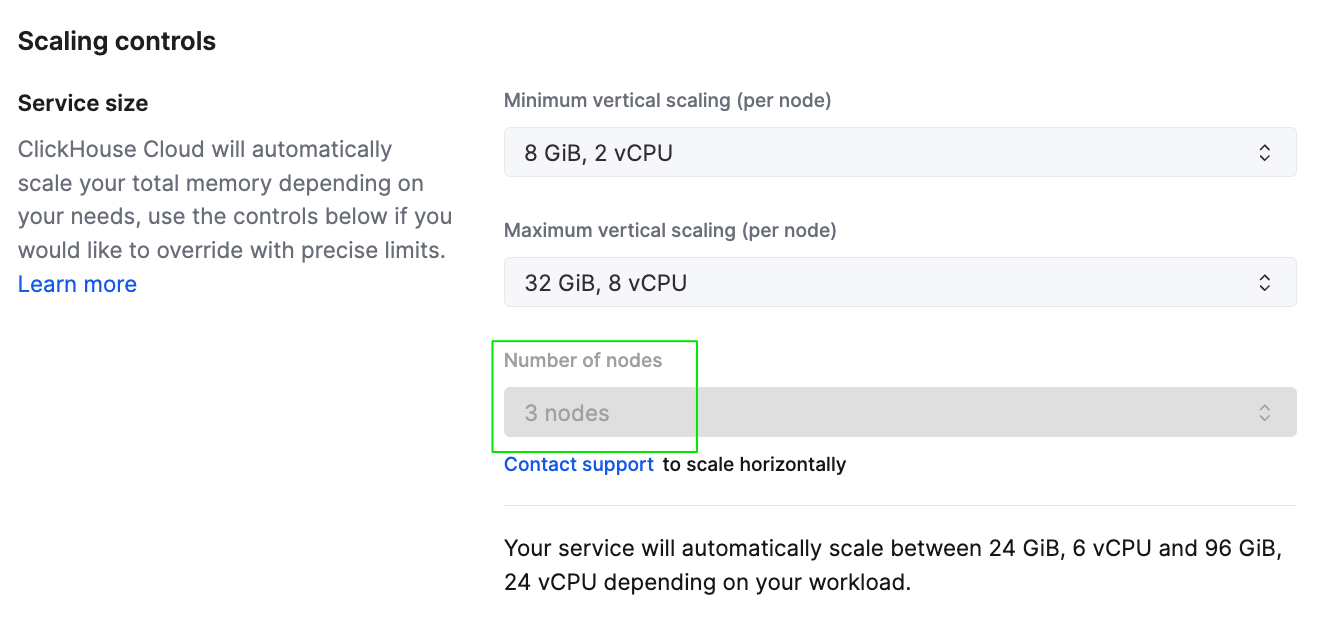
Настройки масштабирования услуги из консоли ClickHouse Cloud
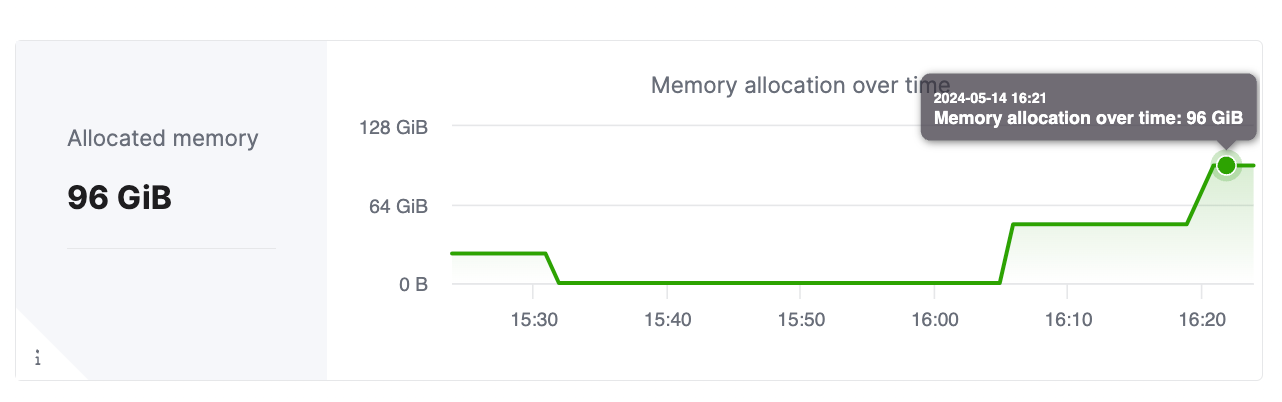
После того как услуга была масштабирована, панель мониторинга метрик в облачной консоли должна показывать правильное распределение на услугу. Снимок экрана ниже показывает кластер, который масштабировался до общей памяти 96 GiB, которая равна 6 репликам, каждая с выделением памяти 16 GiB.
Автоматическое простое состояние
На странице Настройки вы также можете выбрать, разрешать ли автоматическое простое состояние для вашей службы, когда она неактивна, как показано на изображении выше (то есть когда служба не выполняет никаких запросов, отправленных пользователем). Автоматическое простое состояние снижает стоимость вашей службы, так как вы не будете платить за вычислительные ресурсы, когда служба приостановлена.
В некоторых специальных случаях, например, когда служба имеет большое количество частей, служба не будет автоматически переведена в простое состояние.
Служба может войти в состояние простоя, при котором приостанавливаются обновления обновляемых материализованных представлений, потребление из S3Queue и планирование новых объединений. Существующие операции объединения завершатся до того, как служба перейдет в состояние простоя. Чтобы гарантировать бесперебойную работу обновляемых материализованных представлений и потребление S3Queue, отключите функциональность простого состояния.
Используйте автоматическое простое состояние только если ваш сценарий использования может выдержать задержку перед ответом на запросы, потому что когда служба приостановлена, соединения с ней будут время от времени разрывано. Автоматическое простое состояние идеально подходит для служб, которые используются редко и где задержка может быть терпимой. Не рекомендуется для служб, которые поддерживают функции, обращенные к клиентам, которые используются часто.
Обработка всплесковых нагрузок
Если вы ожидаете всплеск нагрузки, вы можете использовать ClickHouse Cloud API для превентивного масштабирования вашей службы для обработки всплеска и последующего уменьшения размера, когда потребность снизится. Чтобы понять текущее использование CPU и памяти для каждой из ваших реплик, вы можете выполнить следующий запрос: